
1. OpenAI Gym Taxi Environment
https://www.gymlibrary.dev/environments/toy_text/taxi/
Taxi - Gym Documentation
Previous Blackjack
www.gymlibrary.dev

OpenAI Gym에서 제공하는 다양한 환경 중 하나인 Taxi (Toy Text) 환경은 위 사진과 같이 구성되어 있습니다.
그리드에는 R(빨강), G(초록), Y(노랑) 및 B(파랑)로 표시되는 4개의 지정된 위치가 있습니다.
에피소드가 시작되면 택시는 임의의 장소에서 출발하고 승객은 임의의 또 다른 장소에 있습니다. 택시는 승객의 위치로 운전하여 승객을 태우고 승객의 목적지(지정된 4개의 위치 중 다른 하나)로 운전한 다음 승객을 하차시키게 됩니다.
승객이 내려지면 에피소드는 끝나게 됩니다.
| Action Space | Discrete(6) |
| Observation Space | Discrete(500) |
환경에 Action Space는 총 6차원 (위, 아래, 왼쪽, 오른쪽 이동 + 손님 태우기, 내려주기) 입니다.
Observation Space는 총 500차원입니다.
25개의 택시 위치(그리드가 5x5), 5개의 가능한 승객 위치(승객이 택시에 있을 때 포함하여 색 4개), 4개의 목적지 위치가 있기 때문에 500개의 개별 상태가 있습니다.
즉 25 * 5 * 4 이므로 총 500차원이 되는 것입니다.
하지만 여기서 한 에피소드 동안 실제로 도달할 수 있는 상태는 400개라고 합니다.
누락된 100개의 상태는 승객이 목적지와 동일한 위치에 있는 상황에 해당하고, 이는 성공한 에피소드이기 때문입니다.
또한, 승객과 택시가 모두 목적지에 도착하면 성공한 에피소드 직후에 네 가지 상태를 추가로 관찰할 수 있다. 따라서 도달할 수 있는 상태가 404개가 됩니다.
각 state는 아래와 같이 튜플로 표시할 수 있습니다.
(taxi_row, taxi_col, passenger_location, destination)+---------+
|R: | : :G|
| : | : : |
| : : : : |
| | : | : |
|Y| : |B: |
+---------+보상(Reward)의 경우 한 스텝당 -1점, 성공적으로 승객을 태우고 목적지에 내려준 경우 +20, 승객 태우기와 내려주기를 의미없이 실행했을 경우 -10점을 받게 됩니다. (예를 들어, 승객이 없는데 태우거나, 승객이 타고있지 않은데 내려주기를 한 경우 등)
2. Policy Iteration
i) Policy Iteration Class
생성자
import gym
from gym import envs
import numpy as np
class PolicyIteration(object):
# constructor
def __init__(self, env):
# environment
self.env = env
# size of each spaces
self.n_act = self.env.action_space.n
self.n_obs = self.env.observation_space.n
# policy table
self.policy_table = np.ones([self.n_obs, self.n_act]) / self.n_act
# value table
self.value_table = np.zeros(self.n_obs)- PolicyInteration 클래스의 생성자에서는 인자로
env를 받아, 클래스의 attribute로 선언합니다. 또한, 각action_space의 크기와observation_space의 크기를 변수로 저장합니다. - policy table의 경우 state에 대한 action에 대한 정보를 저장해야 하므로 observation space 크기 by action space 크기로 선언하고, 각 state에 대해 취할 수 있는 action이 action space의 크기 만큼 있으므로 행렬에 대해 vectorization 연산을 취해 각 원소를 나누어줍니다.
- value table의 경우 어떤 state에서 최적의 action을 저장하고 있어야 하므로 state의 개수만큼의 값을 저장하고 있으면 됩니다. 초기값은 모두 0입니다.
Policy Evaluation Method
def policy_evaluation(self, iter_num : int, discount_factor : float):
for episode in range(iter_num):
for state in range(self.n_obs):
# v_pi(s)
v_s = 0.0
for act, pi_a_s in enumerate(self.get_policy(state)):
sv_s = 0.0
for P_ss_a, next_state, r_s_a, done in self.env.env.P[state][act]:
sv_s += P_ss_a * self.get_value(next_state)
v_s += pi_a_s * (r_s_a + discount_factor * sv_s)
# value[state] <= v_s
self.set_value(state, v_s)
self.print_value()$v_\pi(S) = \sum_{a \in A} \pi(a|s) (r_s^a + \gamma \sum_{s' \in S}P_{ss'}^av_\pi(s'))$
iter_num만큼 학습을 반복합니다.- 모든 state에 대해서 value 값, $v_\pi(s)$인 v_s를 계산합니다.
- 먼저 Action Set 내의 모든 action에 대해 policy 값 즉, $\pi(a|s)$인 pi_a_s를
policy_table에서 가져옵니다.policy_table에는 어떤 state와 action에 대한 $\pi(a|s)$값을 저장합니다. - 두 번째 시그마 $\sum_{s' \in S}P_{ss'}^av_\pi(s')$를 계산하기 위해 합 변수
sv_s를 선언하고 초기화합니다. - self.env.P[state][action]을 통해 어떤 state에서 어떤 action을 취했을 때의 다음 상태로의 전이 확률, 다음 상태, 보상을 알 수 있습니다. 중요한 것은, 이 환경에서 어떤 state에서 어떤 action을 취했을 때는 1의 확률 (반드시) 하나의 다음 상태로 전이됩니다. 하지만, 그렇지 않을 수 있기 때문에, 위 공식에 맞게 계산해주었습니다. (다음 상태가 하나가 아니어도 계산됨)
- $P_{ss'}^a \times v_\pi(s')$를 P_ss_a * get_value(next_state)를 통해 계산합니다. $v_\pi(s')$는 다음 상태인 $s'$의 value값입니다. 그렇기에
get_value()함수를 통해 다음 상태에 대한 value값을 가져옵니다. forloop를 통해 시그마 내의 값을 다 더하면 그 합 값에 감쇄인자인 $\gamma$를 곱해주고 어떤 상태 $s$에서 행동 $a$를- 취했을 때의 보상값인 $r_s^a$를 더해줍니다.
r_s_a + discount_factor * sv_s이 값에 아까 구했던 $\pi(a|s)$를 곱해주고pi_a_s * (r_s_a + discount_factor * sv_s), 모든 action에 대해forloop를 통해 시그마 합 값을 구할 수 있습니다. - 이 값
v_s이 상태 $s$에 대한 value 값인 $v(s)$이므로value_table을 업데이트 해줍니다.
Policy Improvement Method
def policy_improvement(self, discount_factor : float):
for state in range(self.n_obs):
action_values = []
for action in range(self.n_act):
sv_s = 0.0
for P_ss_a, next_state, r_s_a, done in self.env.env.P[state][action]:
sv_s += P_ss_a * self.get_value(next_state)
action_values.append(r_s_a + discount_factor * sv_s)
# greedy
best_action_idx = np.argmax(np.array(action_values))
# one-hot encoding
self.set_policy(state, np.eye(self.n_act)[best_action_idx])
self.print_policy()$\pi'=greedy(v_\pi)$
$\pi' = {argmax}_a(r_s^a + \gamma \sum_{s' \in S}P_{ss'}^av_\pi(s'))$
- 아까와 같이 특정 state에서 취한 특정 action에 대한 value값을 찾고 어떤 state에서 취할 수 있는 action 값을 중, value값을 가장 크게 하는 aciton을 policy가 취하도록 합니다.
- 위의 Policy Evaluate 함수와 같이 계산을 하지만, 하나 다른 점은 policy를 업데이트하기 위한 것이므로, policy의 값인 $\pi(a|s)$를 곱하지 않습니다.
- 위와 같이 시그마 내의 각 다음 상태에 따른 확률과 value값을 곱한 값을 모두 더한 값에 감쇄인자를 곱하고, 보상을 더해줍니다.
- 여기서, 이 값을 최대로 하는 aciton값인 $a$를 ${argmax}_a$를 통해 구해냅니다. 즉, 어떤 상태 $s$에서 어떤 액션인 $a$를 취해야 현재의 보상을 최대로 하는지를 구하는 것입니다.
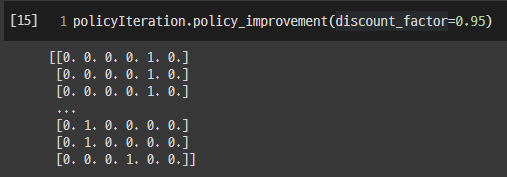
action_values라는 빈 리스트에 각 action에 대한 value값을 순서대로 넣고, 이를 numpy의np.array타입으로 바꾼 후 numpy의np.argmax()함수를 이용해 value값들 중 최댓값을 만드는 action의 번호를 알아내도록 합니다- 이를 one-hot encoding으로 변환해 해당 state에 대해 최적의 policy로 저장합니다.
Print, Get, Set Methods
def print_value(self):
print(self.value_table)
def print_policy(self):
print(self.policy_table)
def set_policy(self, state : int, x : np.array):
self.policy_table[state] = x
def get_policy(self, state : int):
return self.policy_table[state]
def set_value(self, state : int, x : float):
self.value_table[state] = x
def get_value(self, state : int) -> float:
return self.value_table[state]- OOP의 캡슐화 특성에 알맞게 핵심 자료들은
get(),set()함수를 제작하여 접근할 수 있도록 하였습니다.
View Policy Animation Method
def view_policy_anim(self):
done = False
obs = env.reset()
self.frames = []
while not done:
action = np.argmax(self.policy_table[obs])
next_obs, reward, done, info = self.env.step(action)
self.frames.append({
'frame' : env.render(mode='ansi'),
'state' : next_obs,
'action' : action,
'reward' : reward
})
obs = next_obs
for step, frame in enumerate(self.frames):
clear_output(wait=True)
keys = list(frame.keys())
# print
print(frame['frame'])
print(f"step : {step + 1}")
for key in keys[1:]:
print(f"{key} : {frame[key]}")
sleep(0.5)
ii) 메인 코드
from IPython.display import clear_output
from IPython.display import display
from time import sleep
env = gym.make('Taxi-v3')
policyIteration = PolicyIteration(env=env)
policyIteration.policy_evaluation(iter_num=100, discount_factor=0.95)
policyIteration.policy_improvement(discount_factor=0.95)
policyIteration.view_policy_anim()- policyIteration 인스턴스를 gym의
"Taxi-v3"환경으로 생성합니다. - 이후, policyIteration 인스턴스의 각 메서드를 사용해 학습을 진행합니다.
3. 학습 및 검증 (Training and Evaluation)
env = gym.make('Taxi-v3')
policyIteration = PolicyIteration(env=env)
policyIteration.policy_evaluation(iter_num=100, discount_factor=0.95)
policyIteration.policy_improvement(discount_factor=0.95)
policyIteration.view_policy_anim()policy_evaluation과policy_improvement를 번갈아가며 5번 실행했습니다.- value 테이블의 값이 더 이상 크게 변하지 않는 것을 보아 거의 수렴함을 알 수 있었습니다.
policy_evaluation학습 (100번 반복, 5번)

policy_improvement학습 (5번)
- view_policy_anim()
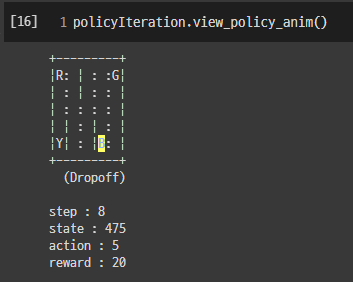
8스텝만에 손님을 올바른 장소에 dropoff하여 에피소드가 성공으로 마무리되었습니다.
4. 비교(Comparison)
i) evaluation과 improvement를 번갈아서 1번씩 총 10번 학습
184.61538462 115.74602671 146.66050962 122.89055443 -20.
115.74602671 -20. 85.03768781 115.74602671 90.56598717
146.66050962 96.38524965 79.78580342 90.56598717 79.78580342
122.89055443 195.38461538 122.89055443 155.43211538 130.41110993
174.38461538 108.95872537 138.32748413 115.74602671 74.79651325[[0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1. 0.]
...
[0. 1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0.]]
학습은 성공적으로 잘 되었습니다.
ii) evaluation 10번, improvement 한 번 학습
-66.26451355 -71.80805336 -71.42091403 -71.82398385 -79.85888468
-79.76658608 -79.85928952 -79.85334816 -78.94858441 -78.98978947
-78.18080416 -78.99084701 -79.89021485 -79.88584063 -79.89044499
-79.81487276 -58.97400656 -71.2834488 -70.42380509 -71.31882251
-71.76862177 -75.09074458 -74.85874041 -75.10029138 -79.84518971[[0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1. 0.]
...
[0. 0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0. 0.]]
학습이 잘 진행되지 않았습니다.
5. 결과 분석
두 value_table의 값이 크게 다릅니다. 또한, 번갈아가며 학습한 것은 학습이 잘 되었는데, 10번, 1번 한 경우는 학습이 잘 되지 않았습니다. 이 이유를 분석해보자면,
policy evaluation 코드 내에 보면
for act, pi_a_s in enumerate(self.get_policy(state)):
sv_s = 0.0
for P_ss_a, next_state, r_s_a, done in self.env.env.P[state][act]:
sv_s += P_ss_a * self.get_value(next_state)
v_s += pi_a_s * (r_s_a + discount_factor * sv_s)
# value[state] <= v_s
self.set_value(state, v_s)위 부분에서 action과 $\pi(a|s)$ 확률 값을 가져올 때, policy_table에서 가져옵니다. 이때, policy_improvement 없이 policy_evaluaiton만 계속 진행하게 된다면, policy_evaluation은 value_table만 수정하므로, policy_improvement가 없다면 policy_table은 초기 상태 그대로여서 value_table 값은 policy가 그대로이므로, 처음에 좋지 않은 policy에 따라 value를 수정할 것입니다.
policy_improvement를 하면, value 값에 따라 policy를 수정해나가므로, 다음 번 policy_evaluation 단계에서 조금 더 좋은 방향으로 수정된 policy에 따라 value를 수정하고, 이 변경된 value를 기반으로 policy를 향상해나가므로 학습이 일어남을 알 수 있습니다.
6. Policy Iteration for estimation $\pi \approx \pi_*$
i) 생성자 수정
$V(s) \in R$ and $\pi(s) \in A$ arbitrarily for all $s \in S$, 알고리즘에 따라 value_table의 초깃값을 실수 난수로 초기화하였습니다.
class PolicyIteration(object):
# constructor
def __init__(self, env):
# environment
self.env = env
# size of each spaces
self.n_act = env.env.action_space.n
self.n_obs = env.env.observation_space.n
# policy table
self.policy_table = np.ones([self.n_obs, self.n_act]) / self.n_act
# value table
# init table with np.random.random()
self.value_table = np.random.random(self.n_obs)
# iteration count
self.iternum = 0
self.improvenum = 0value_table을np.random.random을 이용해 실수 난수로 초기화했습니다.
ii) Policy Evaluation 수정
def policy_evaluation(self, theta : float, discount_factor : float):
# count iteration
while True:
self.iternum += 1
# delta <= 0 --- (1)
self.delta = 0.0
for state in range(self.n_obs):
# v_pi(s)
v_s = 0.0
# v <= V(S) --- (2)
v = self.get_value(state)
for act, pi_a_s in enumerate(self.get_policy(state)):
sv_s = 0.0
for P_ss_a, next_state, r_s_a, done in self.env.env.P[state][act]:
sv_s += P_ss_a * self.get_value(next_state)
v_s += pi_a_s * (r_s_a + discount_factor * sv_s)
# value[state] <= v_s
self.set_value(state, v_s)
# delta <= max(delta, |v - V(S)|) --- (3)
self.delta = max(self.delta, abs(v - v_s))
# loop until delta < theta --- (4)
if self.delta < theta: break
print(f"delta : {self.delta}")- (1) $\triangledown \leftarrow 0$ :
self.delta = 0.0매 iteration마다delta를 0으로 초기화하였습니다. - (2) $v \leftarrow V(s)$ : 새로운 value 함수 값을 구하기 이전 값을 $v$에 저장합니다.
v = self.get_value(state) - (3) $\triangledown \leftarrow \max(\triangledown, |v - V(s)|)$ : 이전 value 함수 값과 새롭게 계산된 value 함수 값의 차이와
delta값 중 큰 값을delta에 저장합니다. - (4) until $\triangledown < \theta$ :
delta가theta보다 작아질 때까지 반복하도록 하였습니다.if self.delta < theta: break
iii) Policy Improvement 수정
def policy_improvement(self, discount_factor : float):
self.improvenum += 1
# policy stable <= True --- (1)
policy_stable = True
for state in range(self.n_obs):
# old_action <= pi(s) --- (2)
pi_s = self.get_policy(state)
action_values = []
for action in range(self.n_act):
sv_s = 0.0
for P_ss_a, next_state, r_s_a, done in self.env.env.P[state][action]:
sv_s += P_ss_a * self.value_table[next_state]
action_values.append(r_s_a + discount_factor * sv_s)
# greedy
best_action_idx = np.argmax(np.array(action_values))
# old action != pi(s) -> policy_stable <= False --- (3)
if not np.array_equal(pi_s, np.eye(self.n_act)[best_action_idx]):
policy_stable = False
# one-hot encoding
self.set_policy(state, np.eye(self.n_act)[best_action_idx])
# self.print_policy()
# if policy_stable, stop and return V, pi else evaluation again
return policy_stable- (1)
policy_stable$\leftarrow$true:policy_stable = True플래그 변수를 두고,true를 저장합니다. - (2)
old_action$\leftarrow \pi(s)$ :pi_s = self.get_policy(state)이전 action에 현재 state에 대한 $\pi$값(policy값)을 저장해둡니다. - (3)
If old_action≠ $\pi(s)$, thenpolicy_state$\leftarrow$false:if not np.array_equal(pi_s, np.eye(self.n_act)[best_action_idx]): policy_stable = False이전 액션 값과 현재 새로 조절한 액션 값이 어떤 state에 대해 하나라도 다르면 플래그를false로 전환합니다. 즉, 모든 state에 대해 이전 aciton과 새롭게 구한 최적 action이 모두 같다면, 모든 state에 대해 대응되는 모든 action이 최적의 action이므로policy_stable을true로 두고 이 값을 반환합니다. - (4)
If policy_stable, then stop and return
iv) 메인 코드
done = False # policy_improvement 내의 policy_stable값과 같게 된다.
count = 0
while not done:
# (2) policy Iteration until delta < theta
policyIteration.policy_evaluation(theta=0.00001, discount_factor=0.95)
# (3) if policy_stable, then stop, else go to (2)
done = policyIteration.policy_improvement(discount_factor=0.95)
count += 1
# if policy_stable, V ~ v*, pi ~ pi*
print(policyIteration.iternum, policyIteration.improvenum, count)- 전체 iteration이 몇 번 돌았는지 기록하기 위해
count변수를 두고 횟수를 셉니다. - policy evalutaion의 경우 인스턴스 내의 변수로 횟수를 셉니다.
- 먼저, 루프 내에서
policy_evaluation메서드를 호출합니다. 이때,theta=0.00001인자로 넘깁니다. - 2번 policy evaluation 과정 내에서
delta< $\theta$ 조건이 만족될 때까지 기다리고, 조건이 만족되었다면 루프가 종료되고 함수는 종료됩니다. 이후 다음policy_improvement함수로 넘어갑니다. 이때, 위에서return policy_stable문을 사용한 이유는 만약policy_stable이true라면true를 반환하고,false라면false를 반환하므로, 이 값을 루프 내에서done변수로 받아주었습니다. - 알고리즘에 따라
policy_stable(=done변수 값과 같음)가true라면while루프를 탈출할 것이고, 만약false라면 다시policy_evaluation()이 호출되어 학습을 반복할 것입니다. - 위 알고리즘 조건에 맞아 루프가 종료되면 현재
value_table이 $v$,policy_table이 $\pi$라고 할 수 있습니다. ( $V \approx v, \pi \approx \pi$ )
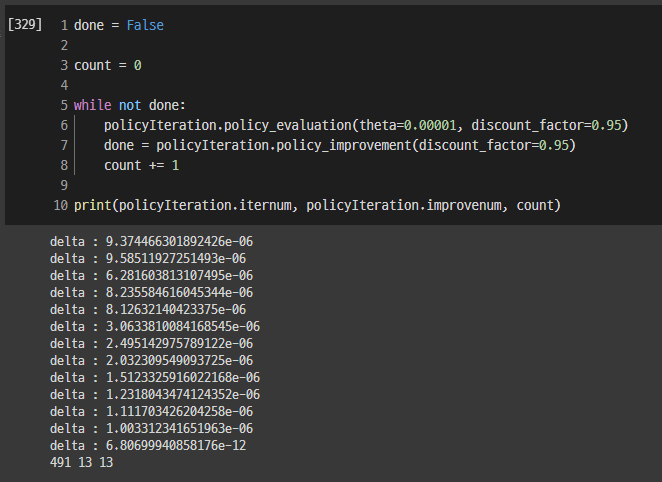
위 코드를 실행한 결과 policy_evaluation은 491번 반복되었고, 메인 코드에서의 while loop는 13번, policy_improvement도 13번 반복하고 학습이 종료되었습니다.

결과를 확인해보니 학습이 잘 되었음을 알 수 있었습니다.