1. 1주차 - EDA, Data Augmentation, Data Balancing
https://deepdeepit.tistory.com/164
Data Creator Camp 2022 1주차 - EDA, Data Augmentation, Data Balancing
대회 설명 https://kbig.kr/portal/kbig/keybiz/creatorcamp.page K-ICT 빅데이터 센터 참가 대상 · 고등부 대학부 모두 4~5인으로 구성된 팀으로만 참가 (선착순 접수) 고등부 · 빅데이터 분석 활용에 관심 있는
deepdeepit.tistory.com
2. 2주차 문제 (Problems) - 실사진과 일러스트 사진 분류
2주차에서는 인공지능(AI) 기술을 활용하여 데이터셋에 섞여있는 잘못된 데이터인 실사진을 분류하고 제거하는 것입니다.
3. 아이디어 (Main Idea)
실사진과 일러스트 이미지를 분류하기 위한 저희팀의 주요 아이디어는 바로 색의 최빈값을 사용하는 것입니다. 여기서 최빈값(Mode)이란 통계학 용어로, 가장 많이 관측되는 수, 즉 주어진 값 중에서 가장 자주 나오는 값을 말합니다.
실제 사진은 사진의 구성이 다양하고, 특히 빛의 명암으로 인해 어둡거나 밝은 부분도 자세히 보면 조금씩 색이 모두 다르게 표현되어 있습니다. 색의 구성이 다양하기 때문에 이산적인 각각의 색이 포함하는 비율이 적을 것입니다.
하지만 일러스트 이미지의 경우 대부분 컴퓨터 장비를 통해 그리므로 명암 표현이 되어있더라도 그 명암을 구성하는 색이 비교적 적고 대부분 배경이 있으며, 색의 구성이 단순하다는 것입니다. 따라서 이산적인 각각의 색이 포함하는 비율이 클 것이라고 생각했습니다.
즉, 정리하자면
실사진
1) 색 중 최빈값을 계산하면 최빈값이 전체 색들 중 차지하는 비율이 작을 것이다.
2) 비슷해보이는 색도 각각 다 다른 값이므로 색의 구성이 다양할 것이다.
일러스트 이미지
1) 색 중 최빈값을 계산하면 최빈값이 전체 색들 중 차지하는 비율이 클 것이다.
2) 색의 구성이 비교적 단순하며, 색의 종류가 적을 것이다.
4. 클러스터링 (Clustering)
사진에서 색의 구성과 최빈값의 비율을 뽑아내기 위해서는 색을 일정 개수의 그룹으로 묶는 클러스터링 작업을 거쳐야 합니다. 클러스터링은 머신러닝의 세 분야 중 하나인 비지도학습(Unsupervised Learning)의 범주에 포함되는 알고리즘입니다. 클러스터링을 하면 일련의 데이터를 유사한 성격을 가진 개체를 묶어 일정 개수의 그룹으로 묶어줍니다.
이미지 데이터도 결국 (R, G, B)의 3차원 튜플로 이루어진 배열이므로 클러스터링이 가능합니다. 여기서 주의할 점은 이미지들끼리 클러스터링을 하는 것이 아닌, 하나의 이미지 내에서 색깔을 클러스터링하는 것입니다.
저희 팀에서는 이러한 방식을 최빈값의 비율을 사용한다고 하여 Mode Rate(mode_rate)라고 명명하였습니다.
5. Mode Rate 시리즈
저희 팀은 총 5개의 mode rate 시리즈를 만들었습니다. 당연히 처음부터 5개 종류를 만들자! 해서 만든 것은 아니고, 맨 처음 만든 basic mode rate를 개선하고, 여러 아이디어를 적용하다보니 5번째 버젼까지 가게 된 것입니다. 그렇다고 해서 최신 버젼인 5번째가 무조건 좋은 것도 아니고, 결국은 여러 mode rate를 조합하여 사용을 하게 되었습니다. 아래는 총 5종류의 mode rate에 대한 아이디어와 구현 코드를 설명하도록 하겠습니다.
i) Mode Rate 1 (K-Means 알고리즘)
각 이미지에서 색의 mode rate를 구하기 위해서는 클러스터링을 해야 하는데 가장 유명한 알고리즘인 K-Means 알고리즘을 사용했습니다.
from sklearn.cluster import KMeans
import cv2Scikit-Learn 라이브러리에서 제공하는 K-Means 모듈을 사용했습니다.
아래 그래프는 클러스터링 결과를 받아 클러스터 데이터(대푯값과 비율)로 변환하여 반환해주는 함수입니다.
def centroid_histogram(clt):
# grab the number of different clusters and create a histogram
# based on the number of pixels assigned to each cluster
numLabels = np.arange(0, len(np.unique(clt.labels_)) + 1)
(hist, _) = np.histogram(clt.labels_, bins=numLabels)
# normalize the histogram, such that it sums to one
hist = hist.astype("float")
hist /= hist.sum()
# return the histogram
return hist
아래는 클러스터 데이터(대푯값과 비율)을 인자로 받아 히스토그램 막대 그래프로 그려주는 함수입니다.
def plot_colors(hist, centroids):
# initialize the bar chart representing the relative frequency
# of each of the colors
bar = np.zeros((50, 300, 3), dtype="uint8")
startX = 0
# loop over the percentage of each cluster and the color of
# each cluster
for (percent, color) in zip(hist, centroids):
# plot the relative percentage of each cluster
endX = startX + (percent * 300)
cv2.rectangle(bar, (int(startX), 0), (int(endX), 50),
color.astype("uint8").tolist(), -1)
startX = endX
# return the bar chart
return bar
아래는 이미지를 인자로 받아 클러스터링을 진행하는 함수입니다.
def analyzeimg(img_dir : str, isprint=False):
# 이미지 오픈
img = Image.open(img_dir)
img = img.convert('RGB')
plt.imshow(img)
img = np.array(img)
w, h, c = img.shape
rate = min(w, h) / 200.
rw, rh = int(w / rate), int(h / rate)
# 이미지 사이즈 조절
img = cv2.resize(img, dsize=(rw, rh))
w, h, c = img.shape
img = img.reshape((w * h, 3))
if isprint: plt.imshow(img)
k = 50 # 클러스터의 개수
clt = KMeans(n_clusters=k) # 클러스터링 오브젝트
clt.fit(img) # 이미지를 클러스터링
hist = centroid_histogram(clt) # 클러스터 데이터 반환
if isprint:
for i, center in enumerate(clt.cluster_centers_):
print(f"{i}, {center} : {hist[i]}%")
if isprint: print("each % :", hist)
# 클러스터 데이터를 그래프로 변환
bar = plot_colors(hist, clt.cluster_centers_)
if isprint:
# show our color bart
plt.figure()
# plt.axis("off")
plt.imshow(bar)
plt.show()
print(len(hist))
print(hist)
# 평균, 최빈값 데이터 출력
avg = sum([clt.cluster_centers_[i] * hist[i] for i in range(len(hist))])
mode = clt.cluster_centers_[list(hist).index(max(hist))]
if isprint: print(f"average : {avg}\nmode : {mode} {int(hist[list(hist).index(max(hist))]*100)}%")
# average, mode, clusters(RGB), hist(each rate), rate of mode color
return avg, mode, clt.cluster_centers_, hist, hist[list(hist).index(max(hist))]*100
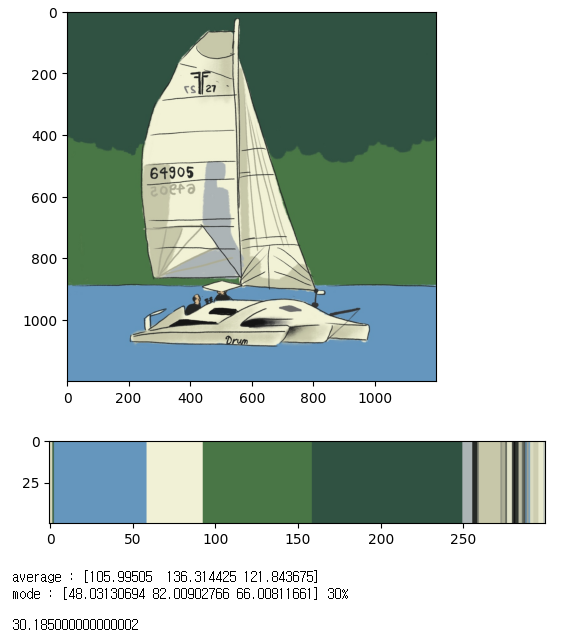
위 코드를 실행하면 아래와 같이 실행됩니다.

위 일러스트 사진을 색에 대해 클러스터링한 결과, 색이 50개의 그룹으로 나뉘었고 그중 가장 큰 비율을 차지하고 있는 최빈값(mode)은 (R, G, B)가 (48.03, 82.01, 66.01)이며 최빈값이 차지하는 비율(mode rate)가 30%인 것입니다.
아래는 실사진을 클러스터링해서 mode rate를 구한 결과입니다.

예상대로 최빈값의 비율인 mode rate가 19.6% 정도로 낮게 나왔습니다.
또한, 여기서 관찰할 수 있는 내용은 하늘의 배경이 비슷한 하늘색임에도 하늘색이 여러 그룹으로 나뉘어져 있다는 것입니다. 이처럼 실사진은 비슷한 색이더라도 자연스러운 명암이 존재하기 때문에 클러스터링을 하면 여러 그룹으로 나뉘어져 mode rate가 낮게 나오게 됩니다.
모든 실사진과 모든 일러스트 사진에 대해 mode rate를 구한 후 분석해보았습니다.
실사진 :
df1['mode_rate'].describe() # 실사
df1.sort_values('mode_rate')count 1925.000000
mean 7.947116
std 4.508251
min 2.932367
25% 5.337224
50% 6.669173
75% 8.868421
max 46.556391
Name: mode_rate, dtype: float64
일러스트 :
df2['mode_rate'].describe() # 일러스트
df2.sort_values('mode_rate')count 23578.000000
mean 75.221210
std 13.330743
min 17.845000
25% 66.715000
50% 76.505000
75% 85.537434
max 99.010000
Name: mode_rate, dtype: float64
sns.distplot(df1['mode_rate'])
sns.distplot(df2['mode_rate'])
plt.show()
위와 같은 그래프가 나오게 됩니다. 생각보다 겹치는 부분이 많고 완벽하게 분류되지 않습니다.
특이한 예외값들을 살펴보면

좌측은 일러스트임에도 mode rate가 18%가 나왔고, 우측은 실사진임에도 mode rate가 45%가 나왔습니다.
이처럼 특수한 예외가 존재하기에 추가적인 방법을 찾아야 했습니다.
ii) XGBoost 머신러닝 학습
지금까지 구한 mode rate와 Data Frame의 일부 attribute를 사용해서 XGBoost 머신러닝(지도학습)을 통해 분류를 해보도록 하겠습니다.
주요하게 사용된 attribute는 아래와 같습니다.
attr = 'numpixel'
sns.distplot(df1[attr])
sns.distplot(df2[attr])
plt.show()
위 그래프는 num pixel 즉 픽셀수에 대한 그래프입니다. 두, 세번째 그래프는 이미지의 width와 height값이고 첫 번째 numpixel 그래프는 두 값의 곱 즉, 실제 픽셀 수(넓이)입니다.
일러스트와 실사진을 비교해보았을때 명확한 차이가 있어 포함하게 되었습니다. 따라서 학습에 사용하는 최종 Data Frame은 아래와 같습니다.
tempdf = df
tempdf.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 25503 entries, 0 to 25502
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 img 25503 non-null string
1 label 25503 non-null string
2 ftype 25503 non-null string
3 cmap 25503 non-null string
4 fsize 25503 non-null float64
5 fmtime 25503 non-null datetime64[ns]
6 width 25503 non-null int64
7 height 25503 non-null int64
8 channel 25503 non-null int64
9 subclass 25503 non-null string
10 mode_rate 25503 non-null float64
11 numcluster 25503 non-null int64
12 avgcolor 16 non-null string
13 modecolors 16 non-null string
14 modehists 16 non-null string
15 isillust 25503 non-null int64
16 numpixel 25503 non-null int64
dtypes: datetime64[ns](1), float64(2), int64(6), string(8)
memory usage: 4.5 MB
string 타입 데이터를 integer 타입으로 변환합니다.
ftypelist = {'jpg':0, 'png':1}
cmaplist = {'RGB':0, 'RGBA':1, 'CMYK':2, 'P':3, 'L':4}
for i, row in tempdf.iterrows():
if tempdf.loc[i, 'ftype'] in ['0', '1']:
continue
tempdf.loc[i, 'ftype'] = str(ftypelist[tempdf.loc[i, 'ftype']])
tempdf.loc[i, 'cmap'] = str(cmaplist[tempdf.loc[i, 'cmap']])
tempdf = tempdf.astype({'ftype':'int', 'cmap':'int'})
여기서 불필요한 attribute 일부를 제거합니다. 그리고 정답 열인 'isillust' 열을 분리합니다.
del tempdf['img']
del tempdf['label']
del tempdf['fmtime']
del tempdf['subclass']
del tempdf['numcluster']
del tempdf['avgcolor']
del tempdf['modecolors']
del tempdf['modehists']
labeldf = tempdf['isillust'] # 정답 열
del tempdf['isillust'] # 특징 df에서 정답 제거
본격적인 머신러닝을 진행합니다. XGBoost 알고리즘과 K-Fold 교차 검증 알고리즘을 사용했습니다.
labeldf = tempdf['isillust'] # 정답 열
del tempdf['isillust'] # 특징 df에서 정답 제거from sklearn.model_selectionimport train_test_split
import xgboostas xgb
from sklearn.model_selectionimport KFold
from sklearn.metricsimport precision_score, recall_score, f1_score, roc_curve, accuracy_score
kf = KFold(n_splits=5, shuffle=True, random_state=42)accuracy_history = []
X = np.array(X)
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.1)
model = xgb.XGBClassifier(booster='gbtree',
colsample_bylevel=0.9,
colsample_bytree=0.8,
gamma=0,
max_depth=15,
min_child_weight=10,
n_estimators=100,
nthread=5,
objective='binary:logistic',
random_state=42,
silent= True)
model.fit(X_train, y_train, eval_set=[(X_val, y_val)])
y_predict = model.predict(X_test)
print("R2 :", model.score(X_train, y_train))
print("Precision :", precision_score(y_test, y_predict))
print("Recall :", recall_score(y_test, y_predict))
print("F1 :", f1_score(y_test, y_predict))
accuracy_history.append(accuracy_score(y_predict, y_test))
print("accuracy of each K :", accuracy_history)
print("average acc :", np.mean(accuracy_history))
머신러닝 결과는 다음과 같았습니다.
# 1st
[99] validation_0-logloss:0.00077
R2 : 0.9998366102064158
Precision : 1.0
Recall : 1.0
F1 : 1.0
# 2nd
[99] validation_0-logloss:0.00086
R2 : 0.9998366102064158
Precision : 1.0
Recall : 1.0
F1 : 1.0
# 3rd
[99] validation_0-logloss:0.00193
R2 : 0.9998910734709439
Precision : 1.0
Recall : 1.0
F1 : 1.0
# 4th
[99] validation_0-logloss:0.00165
R2 : 0.9998910794031152
Precision : 0.9995768091409225
Recall : 1.0
F1 : 0.9997883597883598
# 5th
[99] validation_0-logloss:0.00110
R2 : 0.9998910794031152
Precision : 0.9993656164093889
Recall : 1.0
F1 : 0.9996827075621365
# result
accuracy of each K : [1.0, 1.0, 1.0, 0.9996078431372549, 0.9994117647058823]
average acc : 0.9998039215686274
정확도가 99.98%가 나왔습니다. 하지만 이는 지도학습을 사용한 것이므로 대회에 사용이 불가능했습니다. 왜냐하면 원칙상 어떤 사진이 일러스트이고 실사진인지 알지 못하는 상태에서 구분을 해내야 했기 때문입니다. (사실 궁금해서 그냥 해본 것입니다)
저희 팀은 mode rate를 더 발전시키기 위해 머리를 모았습니다.
iii) Mode Rate 2 (Selective Search)
Mode Rate 2에서는 Selective Search 알고리즘을 사용합니다. Selective Search란 Object가 있을 법한 영역만 찾는 방법입니다. Selective Search에 대한 자세한 내용은 아래 포스팅을 참고하시길 바랍니다.
Selective Search 간단히 정리..
Selective Search - 기존의 exhaustive search의 방식의 비효율성으로 "object가 있을 법한 영역만 찾는 방법"이 제안됨 - 이를 region proposal - 이 후 detector는 1) generic detector로 candidate objects 영역을 찾기 위해 ex
better-tomorrow.tistory.com
즉, 위 알고리즘을 통해 이미지에서 selective search를 하면 여러 개의 범위가 선택됩니다. 선택된 파트의해당 범위 내에서 mode rate를 구하고 모든 값들 중 가장 작은 값을 mode_rate2로 취합니다.
아래 ss_rect_list() 함수는 selective search 모듈의 selective_search() 함수를 사용해서 이미지에서 Object를 뽑아내어 좌표를 반환해줍니다.
def ss_rect_list(path):
img = cv2.resize(np.array(Image.open(path).convert('L').convert('RGB')), (300, 300))
rect_lst = []
_, regions = selectivesearch.selective_search(img, min_size=img.shape[0] * img.shape[1] // 8)
rects = list(set([region['rect'] for region in regions]))
for rect in rects:
lft, top = rect[0], rect[1]
rgt, bot = lft + rect[2] + 1, top + rect[3] + 1
rect_lst.append(img[top:bot, lft:rgt])
return rect_lst
아래 visualize_ss_rect() 함수는 이미지를 읽어 selective search의 결과 이미지에 사각형 이미지를 그려주는 보여주기용 함수입니다.
def visualize_ss_rect(path):
img = cv2.resize(np.array(Image.open(path).convert('L').convert('RGB')), (300, 300))
_, regions = selectivesearch.selective_search(img, min_size=img.shape[0] * img.shape[1] // 8)
rects = list(set([region['rect'] for region in regions]))
green = (125, 255, 51)
img_pal = img.copy()
for rect in rects:
lft = rect[0]
top = rect[1]
rgt = lft + rect[2] + 1
bot = top + rect[3] + 1
img_pal = cv2.rectangle(img_pal, (lft, top), (rgt, bot), color=green, thickness=2)
print('rect cnts:', len(rects))
print(rects)
plt.figure(figsize=(4, 4))
plt.imshow(img_pal)
plt.show()
위 함수와 클러스터링을 통해 Mode Rate를 계산해내는 함수를 합쳐 Mode Rate 2를 계산했습니다.
결과는.. 암담했습니다. 오히려 Mode Rate 1보다 겹치는 교집합 부분이 훨씬 컸습니다.
iv) Mode Rate 3 (Gamma Correction, Selective Search)

gamma correction은 밝기에 관련된 사진의 특성값 중 하나인 gamma값을 조정하는 것입니다. gamma 값이 낮아지면 중·저계조 영역이 더 어두워지고, 1보다 커지면 더 밝게 표현이 된다고 합니다.
저희는 하나의 사진을 gamma값 0.333, 1.000, 3.000 세 값으로 조정하고 세 사진에 대해 각각 mode rate를 구합니다. 세 사진 중 mode rate가 가장 작은 사진을 gimg로 정합니다.

numsel: 1
1th : 27.4125
min mode_rate: 27.4125gimg에 대해서 selective search를 진행하여 모든 selected part에서 각각의 mode rate를 측정하고, 이들 중 가장 작은 값을 개선된 mode_rate3값으로 사용합니다.
v) Mode Rate 4 (Back-Count)
위에서 계산한 Mode Rate 2와 Mode Rate 3은 좋은 성능을 보여주지 못했습니다. 오히려 Mode Rate 1이 가장 좋은 분류 성능을 보였습니다.
여기서 추가적으로 생각해낸 아이디어는 바로 사진의 배경의 유무였습니다. 대부분의 일러스트 이미지는 흰색 또는 검은색의 배경을 가지고 있습니다. 하지만, 실사진은 배경을 가지고 있지 않습니다. 모든 데이터에 일맥상통하는 전제는 아니지만 Mode Rate처럼 경향성을 파악하기 위해 실험을 해보았습니다.
여기서 Back-Count라는 용어는 사진의 네 개의 모서리 중 특정 크기의 픽셀이 검은색 이거나 흰색인 모서리의 개수입니다. isBack이라는 용어는 Back-Count가 0이면 0, 1 이상이면 1로 이분화한 특성입니다. (배경의 유무)

실사진과 일러스트 이미지의 Back-Count값을 구해보았습니다. 파랑색이 실사진이고, 주황색이 일러스트인데 명확하게 차이가 나는 것을 볼 수 있습니다.

Back-Count 특성을 이분화한 isBack 특성 또한 아주 적은 수의 예외를 제외하고는 명확하게 구분이 가능합니다.
여기서 소수의 예외를 찾아보면
위 두 사진이 대표적입니다. 실사진임에도 불구하고 흰색과 검은색 테두리로 인해 Back-Count가 4가 되는 사진이 존재하는 것입니다.

위 그래프는 위에서 사용하였던 width와 height 특성입니다. 일러스트의 경우 자홍색, 실사진의 경우 보라색입니다. 이 또한, 일러스트와 실사진을 구분해서 보면 경향이 크게 차이가 납니다.

위에서는 width, height, mode rate 특성을 지도학습인 XGBoost 알고리즘으로 학습을 시켰지만 여기서는 비지도학습인 K-Means Clustering 알고리즘을 통해 학습을 해보겠습니다. 위에서 말씀드렸듯, 특정 데이터가 실제로는 실사진인지 일러스트인지 알 수 없기 때문에 정답 라벨링이 필요한 지도학습은 사용이 불가능합니다. 다만, 비지도학습의 경우 라벨링이 필요 없기 때문에 사용이 가능합니다.
case i) isBack(0 or 1) + Mode Rate + 기타 특성 조합하여 클러스터링
clt = KMeans(init='k-means++', n_clusters=2)
clt.fit(df3[['isback2', 'mode_rate']])print("accuracy:", accuracy_score(y, predicted))
print("recall:", recall_score(y, predicted))
print("precision:", precision_score(y, predicted))
print("f1:", f1_score(y, predicted))accuracy: 0.9933341175547975
recall: 0.9930867758079566
precision: 0.9997011356843993
f1: 0.9963829787234042클러스터를 2개(실사진과 일러스트)로 하고 비지도학습을 한 결과 정확도가 99.33%가 나왔습니다. XGBoost의 학습 결과보다는 좋지 않지만 정답 라벨링 없이 비지도학습을 통해 학습한 결과 치고는 매우 훌륭한 결과입니다.
정답인 수는 25,333개, 오답은 170개입니다. 여기서 일러스트를 사진이라고 분류한 수가 163개, 사진을 일러스트라고 분류한 수는 7개입니다.
case ii) Back-Count(0 ~ 4) + Mode Rate + 기타 특성 조합하여 클러스터링
clt = KMeans(init='k-means++', n_clusters=2)
clt.fit(df3[['isback4', 'mode_rate']])print("accuracy:", accuracy_score(y, predicted))
print("recall:", recall_score(y, predicted))
print("precision:", precision_score(y, predicted))
print("f1:", f1_score(y, predicted))accuracy: 0.9874132455005293
recall: 0.9864280261260497
precision: 0.9999570058901931
f1: 0.9931464440506438이번에는 정확도가 98.74%가 나왔습니다. 이러한 실험을 통해 배경의 개수인 Back-Count 특성보다는 배경의 유무를 나타내는 isBack 특성과 조합했을 때 더욱 일러스트와 실사진을 구분하는 데에 더 도움이 되는 것처럼 보입니다.
정답은 25,182개, 오답은 321개로 isBack보다 정답률이 조금 낮습니다. 다만, 일러스트를 사진이라고 분류한 수가 320개, 사진을 일러스트로 분류한 수가 1개로 오답의 종류가 크게 차이가 났습니다.
여기서 사진을 일러스트로 잘못 분류한 이미지는 아래 이미지입니다.

우리는 사진을 일러스트로 잘 못 분류하는 경우를 최대로 줄여야 합니다. 왜냐하면 학습에 사용할 데이터에 실사진을 최대한 제거해야 하므로 일러스트를 잘못 분류하는 것보다 사진을 잘못 분류하는 것이 더 위험하다고 볼 수 있습니다.
case i)은 오답 수가 170개로 case ii)의 321개보다 적지만 사진을 잘못 분류한 개수가 7개고, case ii)는 오답 수가 더 크지만 사진을 잘못 분류한 개수가 1개로, case ii)를 사용해야 한다고 볼 수 있습니다.

추가적으로 isBack3라는 특성을 만들어서 테스트도 해보았습니다. isBack의 기준을 0 ~ 1이면 1, 2 ~ 4면 1로 변경한 특성입니다. 이 또한 클러스터링을 통한 예측 정확도는 99.33%로 isBack과 거의 일치하게 나왔습니다.

좌측 그래프는 Back-Count를 사용하여 예측한 Scatter Plot이고 우측 그래프는 실제 일러스트와 실사진을 나타낸 정답 Scatter Plot입니다. 정답률이 99% 이상이라 높아보이지만, 뭉쳐져 있는 대부분의 데이터 때문에 정확도는 높지만, 그래프의 좌측에 Back-Count가 0 또는 1이고 Mode Rate가 50% 즈음인 데이터는 생각보다 많이 틀린 것을 볼 수 있습니다.
vi) Mode Rate 5 (Mode Rate 2 + Mode Rate 3)
저희 팀원이 만든 Mode Rate 5입니다. 멘토링에서 구체적인 수치를 통한 범위 지정이 가능하다고 하여서 지금까지 만든 Mode Rate 2종을 조합하여 일러스트만 뽑아낼 수 있도록 했습니다.
df_final = df[(df['mode_rate2'] >= 31.7622225) | (df['mode_rate3'] >= 40.13755)]
df_del = df[(df['mode_rate2'] < 31.7622225) & (df['mode_rate3'] < 40.13755) & (df['isillust'] == 1)]
print(*[len(df_final), len(df_del)])23336 242위 코드를 통해 남은 일러스트는 총 23336장, 제거된 일러스트는 242장입니다. 1925장의 실사진은 모두 제거되었습니다.
일러스트 중 97.43%를 살려낸 것입니다. 실사진을 모두 제거하면서 일러스트를 최소한으로 제거할 수 있는 최고의 방법이었습니다.
plt.scatter(x=df['mode_rate3'],
y=df['mode_rate2'],
c=df['isillust'],
cmap='tab20c',
alpha=0.6,
s=5)
plt.xlabel('mode_rate3', fontsize=10)
plt.ylabel('mode_rate2', fontsize=10)
plt.axhline(31.7622225, 0, 100, color='lightgray', linestyle='--')
plt.axvline(40.13755, 0, 100, color='lightgray', linestyle='--')
plt.show()
이를 시각화하면 위 산점도와 같이 나타납니다. 파랑색이 제거해야 하는 실사진이고, 회색이 살려야 하는 일러스트입니다. 파랑색이 전부 제거되도록 선을 그어서 제거한 것입니다.
6. 결론 (Conclusion)
위의 과정을 통해 실사진과 일러스트 이미지를 구분할 수 있는 분류기(Classifier)를 만들어보았습니다. 문제에서 인공지능 기술을 사용하라고 해서 어떤 방식을 써야 하나 많이 고민했습니다.
당연히 라벨링이 불가능하니 머신러닝의 대표격 방식인 지도학습은 사용이 불가능하고 따라서 생각했던 것이 비지도학습인 클러스터링이었습니다. (라벨링이 없으니 사용할 수 있는 머신러닝이 비지도학습과 강화학습 뿐인데, 여기 사용할 수 있는것은 당연하게도 비지도학습 뿐이었습니다.)
그러면서 번뜩 떠오른 Mode Rate라는 아이디어를 통해 나름 합리적인 결과를 도출해낼 수 있던 것 같습니다. 사실 대회를 진행하던 4주 중 가장 오랜 시간이 걸린 문제였습니다. (거의 2주 정도 소요) 그래서 마지막 3~4주차 모델 학습에 쓸 시간을 많이 뺏겨 학습에서 좋은 결과를 이루어내지 못했다는 점이 많이 아쉽습니다.
멘토님께서 말씀해주셨는데 대회측에서 생각했던 방식은 YOLO와 같은 Pre-Trained된 모델을 사용하여 물체가 단 한 개 인식되면 일러스트, 물체가 두 개 이상 인식되면 실사진으로 분류하는 방식을 생각했다고 합니다. 너무 생각했던 것과 정반대의 방법이라 약간 충격을 받기는 했으나 그래도 저는 저희 팀이 한 방법이 좋다고 생각합니다.
지금 돌아보면 다양한 과정의 시행착오를 통해 최선의 알고리즘을 만들어내는 것에는 다양한 아이디어와 데이터 분석을 통한 관찰력, 그리고 조금의 코딩 실력이 있어야 한다는 것을 배웠네요.