
2023 공군 해커톤 AI프로그램 (인공지능 공모전) 장려상 수상기 2편이다. 본 편의 글에서는 예선 경연과 예선 발표 평가에 대해 다루고, 3편에서 본선 경연과 발표, 대회 마무리에 대해 다룰 것이다.
예선 경연
예선 경연은 1차, 2차 두 차수로 나누어 진행되었다.
1차는 5/15(월) 09:00 ~ 5/19(금) 12:00, 2차는 5/22(월) 09:00 ~ 5/26(금) 12:00 각 5일간 진행되었다. 예선에는 사전 평가를 통과한 총 24팀이 참가하게 되는데, 아마 GPU 자원의 한계로 각 차수당 12팀씩 두 차수로 진행한 것 같다. 필자의 팀은 팀원 휴가 일정으로 인해 1차에 참가하게 되었다.
참고로, 예선과 본선 경연 문제와 데이터에 대해 자세히 밝히기는 어렵다. 문제와 데이터 자체가 공군에서 직접 사용중인 군 내 데이터이고 대외 유출이 불가능한 보안 자료이기 때문에 잘못하다가는 보안 위반으로 처벌을 받을 수 있다. 때문에 최대한 간략하게 비슷한 데이터를 활용하여 설명하겠다. 이 부분에 대해서는 너그러운 양해를 바란다.
본 블로그 글에 첨부된 모든 이미지는 실제 대회에서 제공된 데이터와 전혀 관련이 없는 인터넷 공개 데이터임을 밝힙니다.
a. 예선 문제 및 평가 방식
예선 문제는 Computer Vision - Image Classification (이미지 분류) 문제이다. 데이터셋은 Doppler-Range Map 데이터이다.
여기서 Doppler-Range Map이란 아래 이미지를 참고하면 된다.

도플러 효과(Doppler Effect)란 파원에서 나온 파동의 진동수가 실제 진동수와 다르게 관측되는 현상이다. 파원이 가까워지면 진동수가 높아지고, 멀어진다면 진동수가 낮아진다. 이러한 도플러값과 파원의 거리를 X-Y축으로 하여 그래프를 그린 것이 바로 Doppler-Range Map 그래프인 것이다.
쉽게 말해 세로(Y)축은 파원과의 거리(km), 가로(X)축은 도플러값(Hz)인 2차원 그래프가 되는 것이다. 색은 신호의 세기(dBJu)로, Jet 컬러맵(최솟값은 파랑, 최댓값은 빨강인 컬러맵)으로 나타내어 진다. 즉, 실질적으로 3차원 그래프인 것이다. (아래 그림 참고)
파란색은 매우 낮은 값의 신호로 배경 노이즈에 가깝고, 빨간색은 높은 값의 신호로 대상체에 가깝다고 볼 수 있다.

쉽게 말해 대상체와의 절대적인 거리와, 레이더와 대상체가 상대적으로 가까워지는지, 멀어지는지에 대한 도플러값(예를 들어 멀어진다면 양수, 가까워진다면 음수가 될 수 있음), 해당 대상체로부터 인식되는 신호의 세기, 세 가지를 동시에 나타낸 그래프이다. 더 자세한 설명은 아래 영상을 통해 알아볼 수 있다.
그래서, 결론적으로 해결해야 할 문제는 Doppler-Range Map을 어떤 대상체에 대한 이미지인지 총 4가지의 카테고리로 분류하는 것이다. 4가지 카테고리는 새(Bird), 사람(Human), 드론(Drone), 선박(Ship)이다.
평가 지표는 Accuracy를 이용하였다. Classification 문제이기 때문에 Accuracy가 가장 대표적인 지표라고 할 수 있다.
참고로, Accuracy는 전체 데이터 중 모델이 올바르게 예측한 데이터의 개수 비율이다. (정답 데이터 개수 ÷ 전체 데이터 개수)
이미지 분류 문제에서 주요 포인트는 아래와 같다.
1. 이미지 데이터 분석 (EDA)
2. 모델, Optimizer, Loss Function 선택
3. 데이터 전처리 (Preprocessing)
4. 데이터 증강 (Data Augmentation)
5. Hyperparameter Optimization (Tuning)
6. 학습 결과 분석
b. 데이터 분석 (EDA)
주어진 학습용 Train 데이터는 총 144,000개이고 이미지의 Shape은 32 × 32 × 3이다. 여기서 3은 채널의 개수로 각각 R(ed), G(reen), B(lue) 채널을 의미한다.

또한, 클래스별 데이터 개수가 각각 35,921, 36,126, 35,957, 35,996개로 평균이 36,000개 표준편차가 77.43개로 거의 균등하다. 따라서 추가적인 Data Balancing 작업(데이터 증강, 감소 등을 통해 데이터 개수를 강제적으로 조정하는 작업)이 필요하지 않다고 판단하였다. (먄약 각 클래스 별 데이터 개수가 크게 차이났다면 Over, Under Sampling 등을 통한 balancing 작업을 고려했을 것이다)
또한, 4개 카테고리에 대한 이미지 데이터를 직접 살펴본 결과 (보안상 데이터를 직접 공개할 수 없으므로 양해를 바란다) 각 카테고리별로 특성이 존재하였다.
- 사람 : 상대적으로 가로로 긴 모양이 드러난다
- 드론 : 원에 가까운 모양
- 새 : 비교적 모양이 작고 타원에 가깝다
- 선박 : 세로로 두 개의 원이 붙어있는 모양새를 띈다
대부분 이미지 데이터는 사람이 육안으로도 구별이 어려울 만큼 대상 모양이 뚜렷하게 나타나지 않고 자글자글한 노이즈로 가득하다. 따라서 위에서 언급한 특성이 잘 드러나지 않는 대부분의 이미지를 명확하게 분류하는 것이 포인트이다.
c. 데이터 전처리 (Preprocessing)
데이터 전처리에 대해 설명하기 이전에 Doppler-Range Map의 컬러맵인 Jet Colormap에 대하여 설명하도록 하겠다.

Colormap(컬러맵)이란 1채널의 흑백 Gray Scale 이미지를 보여줄 때 적용하는 색의 조합, 즉 색 테마이다. Jet Colormap은 최솟값(0)을 파란색(#0000FF), 최댓값(255)을 빨간색(#FF0000)으로 연속적인 스펙트럼을 갖는 Colormap의 한 종류이다. 최솟값부터 최댓값이 위 그림의 스펙트럼으로 구성되어 있다.
즉, Doppler-Range Map 그래프는 다양한 색을 가진 것처럼 보이지만 사실은 흑백 1채널 이미지에 Jet Colormap을 적용한 것이다. 이때, 위에서 설명했듯 색은 수신 세기의 값을 나타낸다. 따라서, 주어진 데이터는 32 × 32 × 3이 아닌 실질적으로 32 × 32 × 1의 Shape을 갖는 1채널 데이터였던 것이다.
이미지를 인공지능에 학습시킬 때 3채널 이미지를 학습시키는 것보다 1채널 이미지를 학습시키는 것이 더 유리한데, 당연하게도 데이터셋의 크기 자체가 작아지므로 학습 시 할당해야 하는 GPU의 메모리의 크기도 작아지고, 모델도 더 잘 학습할 수 있게 된다. 물론, 채널을 줄이는 것의 이점보다 채널을 줄임으로써 잃게 되는 데이터의 손실이 크다면 줄이지 않는 것이 맞다. (상황에 따라 다르겠지만)
다만, 주어진 데이터는 Jet Colormap이 적용된 본래 1채널 데이터이므로 1차원으로 줄여도 손실이 없다. 따라서 1채널로 줄이는 것이 무조건 유리하다고 판단하였다.
이때, Jet Colormap을 단순 변환을 통해 흑백 Gray Scale로 변환하게 되면 몇 가지 문제가 생긴다.


위 두 장의 이미지를 보자. 위쪽 사진(그림 6)이 단순히 Gray Scale로 변환한 이미지이다. 보면 최솟값(0)과 최댓값(255)이 같은 진회색으로 변환된 것을 확인할 수 있다. Jet Colormap의 색 구조 자체가 대칭적으로 구성이 되어있으므로 흑백으로 변환하면 이 대칭 구조가 그대로 유지된다. 또한, 가장 낮은값과 가장 높은 값이 극값(0 또는 255)가 아니라 회색 계열이므로 색을 표현하는 범위도 크게 줄어든다.
이때, 문제점이 발생한다. 기존의 원본 이미지 데이터에서 다른 값을 가지던 두 값이 Gray Scale 변환을 거치면 같은 값이 되어버린다. 예를 들어, 0값과 255이던 값이 변환 후에는 똑같은 값을 변환되어 버린다는 것이다. 이는 Jet Colormap의 구조 자체의 문제라 다른 방법을 사용해야 한다.
이러한 문제를 해결하기 위해 수학적인 특성을 기반으로 새로운 알고리즘을 개발하였는데 이를 Jet2Gray 알고리즘이라고 명명하겠다. Jet2Gray는 R, G, B의 비선형적인 구조를 변환하여 전체적인 변환을 변경하여 선형적으로 변환하는 알고리즘이다. 아래쪽 사진(그림 7) 보면 위쪽 사진(그림 6)과는 다르게 변환된 흑백 스펙트럼이 선형적인 것을 확인할 수 있다. 즉, 최솟값(0)은 검정색(0)으로 최댓값(255)는 흰색(255)으로 올바르게 1대1로 변환되는 것을 볼 수 있다. 또한, 색의 범위가 0(검정)에서 255(흰색)으로 올바르게 확장되었다.
다음으로 두 번째 전처리인 Noise Reduction이다. 말 그래도 이미지에서 노이즈를 줄이는 것이다.

Range Doppler Map 이미지에서 노이즈는 대부분을 차지하고 있으며 필자 팀은 큰 의미가 없다고 판단하였다. 이미지 데이터는 0 ~ 1 (0/255 ~ 255/255) 의 값을 가지므로 이미지 데이터를 4제곱하여 사용하면 대부분의 노이즈가 제거된다. 즉, y = x를 y = f(x), f(x) = x^4에 맵핑하는 것이다.

이는 실제로, 사진 작가분들께서 사진 보정 시 사용하는 히스토그램 그래프 보정법과 유사한 방식이다.
결과적으로, 위 전처리를 통하면 비교적 작은 값을 가지는 대부분의 노이즈값은 더 작아지고, 큰 값을 가지는 중요한 정보는 비교적 큰 값으로 남아있게 되므로 노이즈를 감소시킬 수 있다.
d. 데이터 Augmentation
필자는 아래와 같은 Augmentation 기법들을 사용했다.

1. Vertical Flip (확률 40%)
2. Horizontal Flip (확률 40%)
3. Random Rotate (확률 40%, 최대 ±5°)
4. Random Brightness (확률 40%, 밝기 최대 ±20%)
5. Random Contrast (확률 40%, 대비 최대 ±20%)
6. Cutout (확률 30%, 박스 최대 10×10 pixel)
위 6개의 기법은 가장 좋은 점수가 나왔던 기법 조합이며, 여러 기법을 넣고 빼며 여러 번의 실험을 통해 결정하였다.
Vertical Flip은 수직으로, Horizontal Flip은 수평으로 뒤집는 것이다. 필자는 어떤 종류의 Flip Augmentation을 사용하여도 된다고 생각하였지만, 발표 심사 때 위 이미지는 하나의 그래프이므로 좌우로 뒤집는 Horizontal Flip은 X-Y축이 뒤바뀌기 때문에 사용하면 안된다고 하였다. 실험 결과는 Flip을 사용하여도 크게 모델의 성능이 증가하지는 않았다.
Random Rotate는 이미지를 특정 확률로 특정 범위 내의 랜덤한 각도만큼 회전하는 것이다.

이때, 이미지를 회전해도 이전과 같은 이미지 크기를 유지해야 하므로 빈 공간이 생기게 된다. (그림 11의 가운데 이미지 참고)
이러한 빈 공간을 채우는 여러 방법이 있는데 유명한 방법으로는 기존의 이미지 위에 덧붙이는 방법 (그림 11의 좌측), 빈 공간은 0(검정) 또는 1(흰색)으로 채우는 방법 (그림 11의 가운데), 이미지를 회전하며 확대하여 기존 이미지 크기만큼 크롭해서 사용하는 방법 (그림 11의 우측), 빈 공간을 맞닿아있는 부분을 반사시켜 채우는 방법 등이 있다. 필자의 팀은 가장 일반적인 방법인 확대하여 크롭하는 방식을 택했다.
Random Brightness, Random Contrast는 이름 그대로 특정 범위 내 랜덤하게 이미지의 밝기와 대비값을 변경하는 것이다. 비슷한 기법으로는 색조, 색온도, 채도, 선명도, 선예도 등 사진 보정 시 사용하는 사진의 여러 보정값을 조정하는 방법이 있다.

마지막으로 유명한 Augmentation 기법 중 하나인 Cutout은 이미지에서 임의의 사각형 부분을 아얘 날려버리는 것이다. 작년 Data Creator Camp에서 처음 접했을 때는 이것이 과연 의미가 있을 것인가 의심이 있었다. (직관적으로 이해가 가지 않았다)
워낙 좋다고 알려진 Augmentation이라 이번 대회에서도 검증을 거쳤고, 성능 향상이 확인되어 추가하였다.
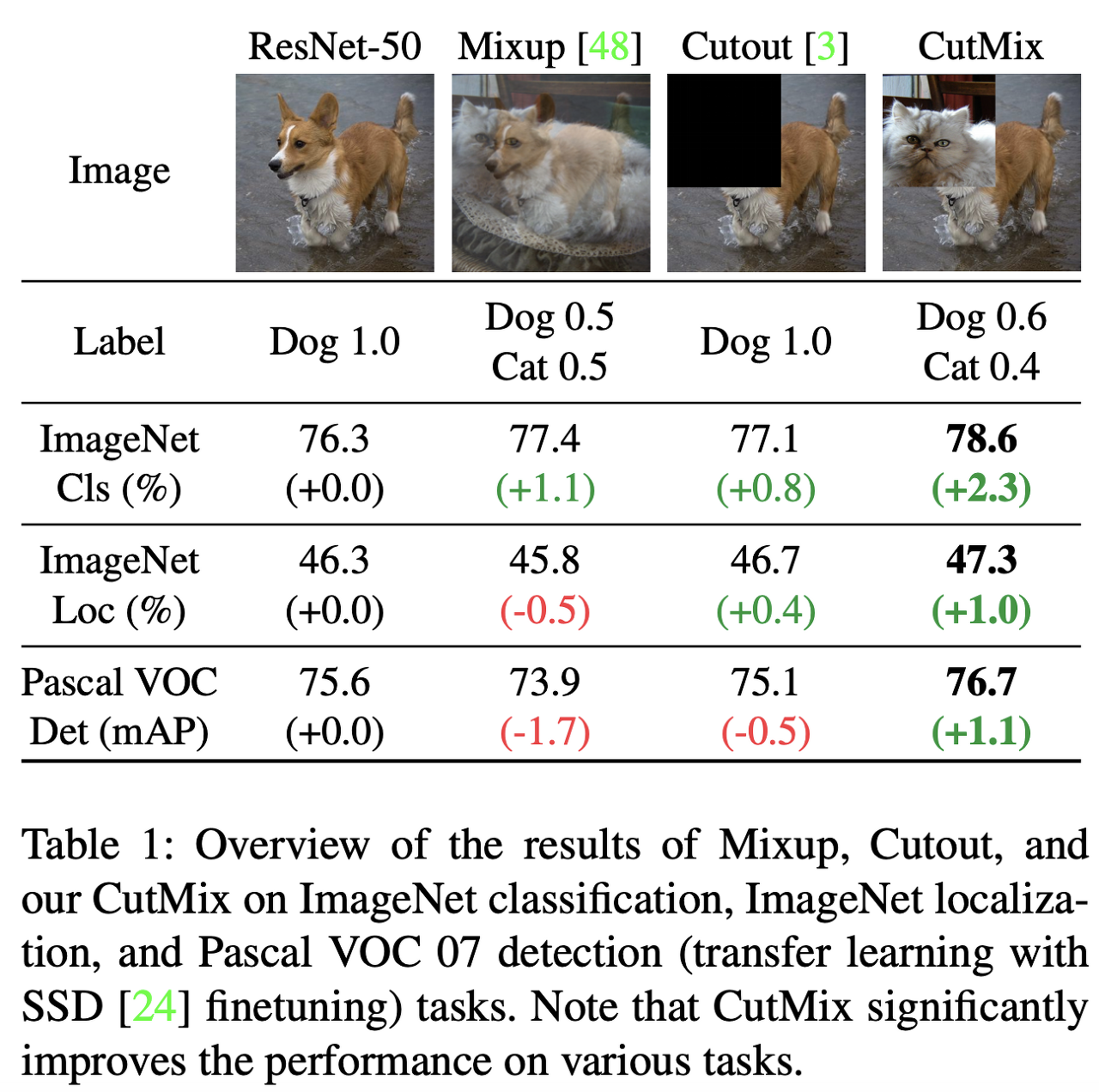
Cutout을 제외하고도 Mixup과 CutMix이라는 Augmentation 기법이 있다. 두 기법 모두 유명한 기법이고, 잘 사용하면 큰 성능 향상을 기대할 수 있다.
다만, 이번 대회에 사용할 수 없었던 이유가 있다. 두 기법은 두 개의 다른 클래스를 가지는 이미지를 섞는 방식을 사용하는데 이러면 정답 Label의 구조도 달라져야 했다.
예를 들어, 그림 13의 CutMix 이미지를 보면 Dog 클래스의 이미지 0.6, Cat 클래스의 이미지가 0.4 비율로 섞여있다. 그러면 정답 또한 [Dog, Cat, ...]이라면 [0.6, 0.4, 0, ...]과 같이 되어야 한다. 필자 팀은 저번 글에서도 말했듯이 이미지 관련 대회에 경험이 없었기도 하고 예선 기간이 1주일로 짧았기 때문에 적용해볼 시간이 부족하다고 판단하였다.
성능 향상이 좋다고 잘 알려진 기법이니 만큼, 다른 Classification 대회에 참가하게 된다면 꼭 사용해보려고 한다.
e. 모델 선택 (Model Selection)
필자의 팀이 사용한 모델은 Xception 모델이다. 필자 팀은 Xception 뿐만 아니라 EfficientNet, ResNet, Inception 등 여러 종류의 모델을 통해 실험해보았다. 그 중 Xception 모델의 성능이 가장 좋아서 선택하게 되었다.
https://www.tensorflow.org/api_docs/python/tf/keras/applications/xception/Xception
tf.keras.applications.xception.Xception | TensorFlow v2.14.0
Instantiates the Xception architecture.
www.tensorflow.org
Xception 모델을 간단히 설명해보겠다.
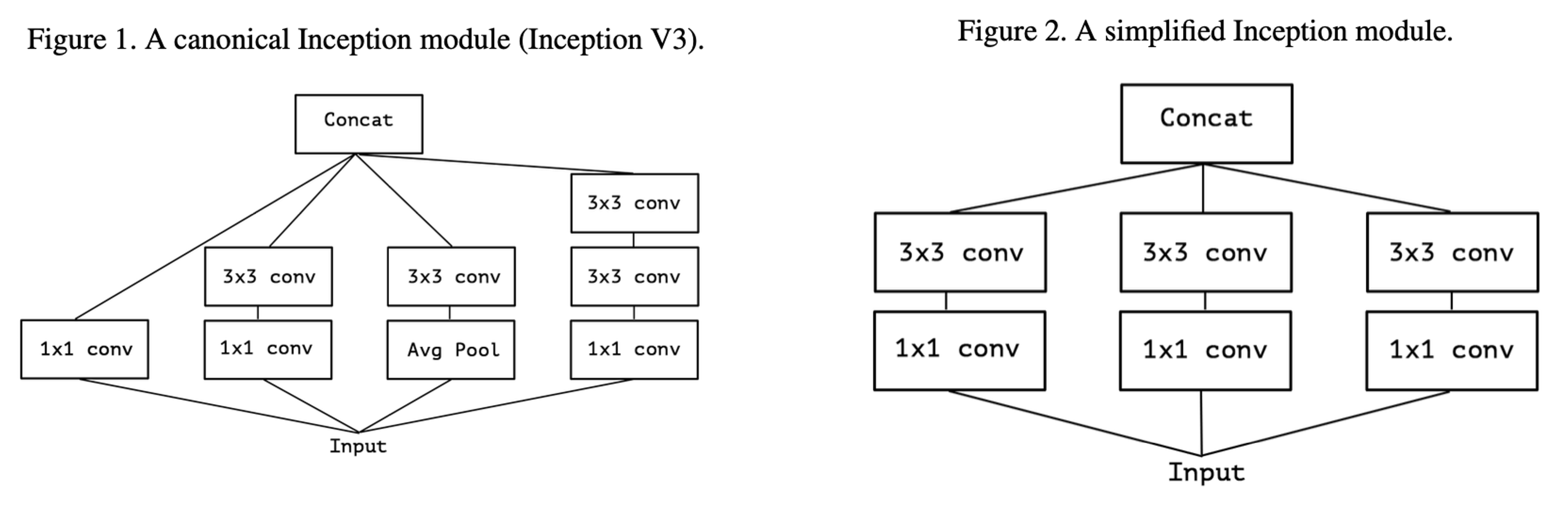
- 모델의 성능을 향상시키기 위해 모델의 사이즈를 키우면 계산 자원이 증가하고 과적합(Overfitting)이 발생하기 쉬워짐
- 이미지에서 노드 사이에 cluster를 형성해 연관성이 높은 부분은 밀도있게, 그렇지 않은 부분은 느슨하게 연상하는 방식. 연관성이 높은 부분은 1×1 필터를, 멀리 떨어진 부분은 3×3 또는 5×5 필터를 사용
- 연산해야 하는 노드들을 1×1 필터로 줄여주고, 계산량이 높은 Convolution들을 계산


- Xception은 Inception 모델에 기반해 Depthwide Separable Convolution을 수정하여 만든 모델
- 채널간의 상관관계를 1×1 Convolution을 이용해 파악하고, 채널이 분리되면 각각의 3×3 Convolution을 수행
- 각 채널별로 Feature Map을 하나씩 만들고, Pointwise Convolution을 이용해 Feature Map 수를 조정

- Xception은 총 14개의 모듈과 36개의 Convolution Layer로 구성되어 있음
- 입력 데이터는 Entry Flow → Middle Flow (×8) → Exit Flow 로 출력된다.

- Depthwise Separable Convolution은 Depthwise Convolution 이후 Pointwise Convolution을 수행하는 반면, Xception 모델은 그림 21과 같이 Pointwise Convolution 이후 Depthwise Convolution을 수행하는 것이 차이
- Inception 모듈은 1×1 Convolution 이후에 활성화 함수인 ReLU를 사용하지만, Xception은 사용하지 않음. 신경망이 깊을 땐 비선형 함수가 도움이 되지만 1개의 채널을 사용하는 Depthwise Separable을 수행할 때는 성능을 해치기 때문에 사용하지 않음
- Inception과 Xception의 parameter 규모는 비슷하지만, Xception이 성능 상 약간의 이점을 가진다고 평가
- ResNet50등의 모델 등을 작성하여 성능을 비교한 결과, 더 좋은 성과를 내었음
설명이 길었지만, 간단하게 말해서 필자의 팀은 EfficientNet, ResNet, Inception, Xception과 각 모델의 몇몇 Variation들을 가지고 간단한 성능비교 실험을 거쳐 가장 좋은 성능이 나온 Xception 모델을 선정하여 사용하였다. 이에 대한 자세한 비교는 아래 작성하겠다.
위에서 계속 언급했듯 이번 대회는 필자의 팀이 본격적으로 참가한 첫 대회였다. 첫 대회 참가였기에 인공지능 공모전에 대한 방법을 몰랐다. 대회 기간 중 얼마만큼을 모델 선정에 써야하며, 어떤 모델을 사용해야 하며, 성능 비교는 어떻게 하는지 아얘 몰랐다.
그래서 대회 기간 중에 엄청나게 바빴다. 모델도 조사해야 하고, 얼마 되지도 않는 GPU로 여러 모델을의 성능을 비교하고 여러 Augmentation 기법에, 만든 전처리 기법까지 비교하느라 정말 시간이 없었다. 이번 대회를 통해 알게된 것은 모델 선정 또한 중요하지만, 더 중요한 것은 빠른 모델 선정 후 경량화 및 추가 기법들을 적용시켜가며 모델의 성능을 끌어올리는 것에 집중을 해야 한다는 것이다.
참고로, 예선 경연에서는 Pre-trained된 모델을 사용할 수 없었다. 모델 코드만 가져와서 처음부터 학습을 시켜야 했다. Pre-trained 모델을 사용하지 않고 조금만 학습시켜도 높은 정확도가 나오긴 하였다.
모델을 선택할 때 모델 성능 지표 점수 (accuracy 등) 뿐만 아니라 모델의 크기와 학습 속도를 중점으로 보고 모델을 선택하였다. 이번 예선 경연 뿐만 아니라 일부 인공지능 공모전과 해커톤은 기간을 짧게 주는 경우가 있다. 따라서 모델의 크기와 flops 등을 보고 모델을 고르면 더 가벼운 모델을 빠르게 학습하거나, 무거운 모델로 더욱 높은 정확도를 노리거나 다양한 시도가 가능하다.
필자는 평소 인공지능 작업 시 Pytorch를 사용한다. 다만, 예선 1차 경연 진행 첫 날 Pytorch 버전과 의존성 오류로 인하여 Pytorch 사용이 불가능하였다. Pytorch가 언제 복구될지 모르는 상황이었고, 예선이 1주밖에 안되었기에 시간이 부족하였다. 따라서, 다른 팀원이 사용하던 Tensorflow와 Keras로 예선 경연을 진행하게 되었다. (Pytorch 오류는 첫 날 오후중에 복구되었으며, CUDA 버전과의 충돌인 것으로 예상된다)
f. 학습 (Training Trials)
학습 시 적용한 추가 기법은 아래와 같다.
먼저, Learning Rate Scheduler이다. LR Scheduler란 학습이 진행됨에 있어서 학습률 즉 learning rate값을 조정해줌으로써 모델이 과적합(Overfitting)되지 않고 잘 학습되도록 해주는 도구이다.

Pytorch에서는 위 그림과 같이 매우 다양한 종류의 Scheduler를 제공하고 있다. 필자의 팀은 보편적으로 널리 사용되는 두 가지의 RL Scheduler를 사용하였다.

ReduceOnPlateau는 그림 23 (좌측 그래프)에서 볼 수 있듯, 일정 Step 또는 Epoch마다 일정 비율로 감소시키는 것이다. 대부분 사용 시 일정한 간격을 고정하지 않고, validation accuracy가 일정한 epoch동안 감소하지 않는 경우 학습률을 감소시킨다.
RampUpAndStepDecay는 그림 24 (우측 그래프)에서 볼 수 있듯, 초반에 학습률을 크게 증가시킨 후, 짧게 이를 유지한다. 이후, 학습률을 특정 비율에 따라 천천히 감소시키는 것이다. RampUpAndStepDecay는 Kaggle에서 아주 인기있는 Scheduler 중 하나이다.
필자의 팀의 학습 전략은 아래와 같다.
1. 적절한 모델과 Optimizer, Loss Function 선택
2. Batch Size, Learning Rate 지정
3. Learning Rate Scheduler 사용 및 튜닝
4. 적절한 이미지의 Input Shape 지정 (필요 시 변환)
5. 데이터 전처리 (Jet2Gray, Noise Reduction)
6. 데이터 증강 (Augmentation)
* Optimizer는 Adam Optimizer, Loss Function은 CrossEntropyLoss를 사용하였다.
* Batch Size와 Learning Rate는 모두 학습에 영향을 주므로, 실험 시 Batch Size를 고정하고 Learning Rate를 고정한다.
* 데이터 전처리와 Augmentation은 원본 이미지와 비교하여 유의미한 모델 성능 향상이 있는지 실험한다.
- 하나의 parameter만 변인으로 두고, 나머지 parameter는 고정한 채 경연의 metric인 validation accuracy를 비교한다.
→ 실험 결과, validation accuracy가 높은 모델과 validation loss가 낮은 모델을 비교했더니, 대체적으로 validation accuracy가 높은 모델이 제출 점수(리더보드 상 Public 점수)가 높은 경향이 있었음.
- 모델을 학습하고 validation accuracy가 가장 높으면서 overfitting이 발생하기 직전의 지점을 찾는다.
- 해당 지점에서 Dropout과 같은 여러 규제(Regulation)과 추가 기법을 적용하여 overfitting을 방지하면서 모델의 학습이 지속되어 성능이 향상될 수 있도록 하였다.
- 모델의 training accuracy가 1에 수렴해버리면 더 이상 모델의 학습이 진행되지 않으므로 학습률을 낮추고, augmenation과 전처리를 추가하여 overfitting을 방지하였다.
g. 결과 (Result)
필자의 팀은 위 전략에 따라 약 20여개의 실험 중 의미있는 결과를 추려 정리해보았다.
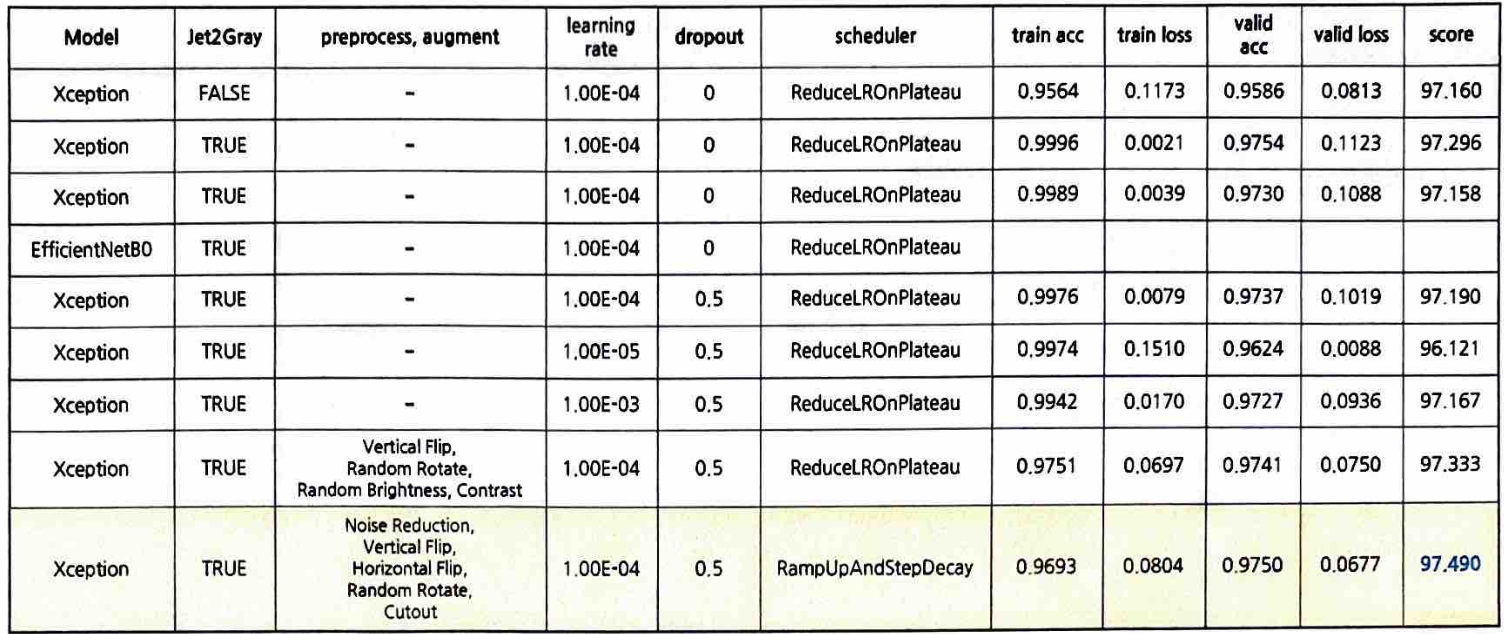
위 표에서 아래 사항은 동일하다
- Batch size : 32
- Optimizer : Adap Optimizer
- Loss : CrossEntropyLoss
- Input Shape : (224 × 224 × 3)
Trial #1 - EfficientNetB0 vs Xception

- EfficientNetB0 모델은 Validation Accuracy가 높게 상승하지 못하고 과적합(Overfitting)이 일찍 발생하였다.
- Xception 모델은 과적합이 발생하지 않고 Validation Accuracy가 1에 가깝게 수렴하였다.
Trial #2 - Learning Rate

- Learning Rate가 1e-3인 경우, 불안정안 학습 형태를 보여주었다.
- Learning Rate가 1e-5인 경우 너무 학습 속도가 더디었고, Validation Accuracy가 크게 증가하지 않았다.
- Learning Rate가 1e-4의 경우 가장 좋은 성능을 보였다. (최종 Public Score 97.190점)
Trial #3 - Original vs Jet2Gray

- Jet2Gray 알고리즘을 통해 변환한 이미지를 사용해 학습한 모델 성능이 크게 향상되었다. (Public Score 0.498점 향상, 최종 Public Score 97.296점)
Trial #4 - Augmentation 적용 여부

- Jet2Gray 알고리즘 적용 이후 Augmentation 적용 모델과 적용하지 않은 모델을 비교한 결과 성능이 향상되었다.
학습 기록 상의 Validation Accuracy는 낮았지만 제출 Public Score가 더 높았다. (최종 Public Score 97.333점)
Trial #5 - Noise Reduction 전처리 적용 여부

- Jet2Gray와 Augmentation 적용 이후, Noise Reduction 알고리즘을 적용하여 모델 성능이 소폭 향상되었다. (약 0.16점)
학습용 데이터 이미지에서 노이즈를 줄여주는 것이 모델 성능 향상에 도움이 되었다. (최종 Public Score 97.490점)
가장 성능과 점수가 좋았던 Trial은 아래와 같다.
- Model : Xception (Optimizer: Adam, Loss Funcion: CrossEntropyLoss)
- Input Shape : (224, 224, 3)
- Augmentation : Vertical Flip, Horizontal Flip, Cutout, RandomRotate
- Preprocess : Jet2Gray, Noise Reduction
- TTA : 사용 안함
- Batch Size : 32
- Learning Rate Scheduler : RampUpAndStepDecay
학습 결과
- Train Accuracy : 0.9963
- Validation Accuracy : 0.9750
- Train Loss : 0.0804
- Validation Loss : 0.0677
리더보드 점수
- Public Score : 97.490
- Private Score : 97.362
- Final Score : 97.413 (최종 24팀 중 9위)
* Final Score는 Public Score 60% + Private Score 40%
최종 24팀 중 9위로 예선 경연을 마무리하였다.
사실 예선 1차시 종료 이후 12팀 중 6위였다. 예선 참가 팀 24팀 중 14팀만 발표 평가에 참가하므로 안정권은 아니었다.
다만, 예선 2차시까지 진행된 후 최종 9위로 마무리하여 예선 발표 평가에 참가하게 되었다.
예선 발표 평가
예선 경연을 통해 리더보드 상 Final Score 상위 14팀이 발표 평가에 참가한다. 이후, 발표 평가와 합산 점수 (비율 비공개)를 바탕으로 상위 12팀이 본선에 진출하게 된다.
예선 발표 평가는 계룡대에서 진행하였다.

계룡대 이외 지역 참가팀은 계룡대 정문에서 모인 후, 차량을 타고 들어갔다.
이후, 지하 1층 대기장소에서 기다리다가 1층 교육장에 모여서 대회 문제에 대한 간단한 설명을 들었다. 이후 1팀씩 발표를 진행했다. 발표는 1팀당 발표 10분, 질의응답 5분으로 진행되었다.
아마 예선 발표 순서는 리더보드 발표 순서에 일부 변경이 있었던 것 같다. 오전에 3팀, 오후에 11팀이 발표를 진행하였다. 필자의 팀은 정확하지는 않지만 6~8번째로 발표를 진행하였던 것으로 기억한다.
심사위원 분들은 민간분야에서 인공지능 연구 및 개발을 하시는 연구원 2분과 군 내 전문가 3분 총 5분이 계셨다.
발표는 예정대로 잘 진행했지만 시간이 조금 넘었다. 아마 첫 대회와 발표인 만큼 1~2분 오버된 것은 봐준 듯 하다. 질의응답은 큰 내용은 없이 대회를 어떻게 진행했는지에 대해 많이 물어봐주셨다.
기분이 좋았던 것이 전문가분들께서 대회를 처음 진행했음에도 데이터 분석과 전처리가 아주 훌륭하다고 칭찬해주셨다.
첫 대회임에도 심사위원 분들께서 칭찬을 많이 해주셔서 기분좋게 마무리할 수 있었다.
이후, 예선 결과가 발표되었다. 발표에서 좋은 평가를 들었지만 큰 비율을 차지하는 리더보드 순위가 9위였기에 마냥 확신하고 있지는 않았다. 다행히도 예선 최종 6위로 본선에 진출할 수 있게 되었다.

이후, 3화에서는 본선 결과와 수상 및 워크샵에 대해 작성하도록 하겠다.
긴 글을 읽어주신 모든 분들께 감사드리며, 질문 사항은 편하게 댓글로 달아주시면 답변드리도록 하겠습니다. 감사합니다!