
https://arxiv.org/pdf/2306.04137.pdf
Abstract
The development of urban-air-mobility (UAM) is rapidly progressing with spurs, and the demand for efficient transportation management systems is a rising need due to the multifaceted environmental uncertainties. Thus, this paper proposes a novel air transportation service management algorithm based on multi-agent deep reinforcement learning (MADRL) to address the challenges of multi-UAM cooperation. Specifically, the proposed algorithm in this paper is based on communication network (CommNet) method utilizing centralized training and distributed execution (CTDE) in multiple UAMs for providing efficient air transportation services to passengers collaboratively. Furthermore, this paper adopts actual vertiport maps and UAM specifications for constructing realistic air transportation networks.
- UAM은 빠르게 개발되고 있지만, 환경의 불확실성으로 인하여 효율적인 교통 관리 시스템(transportation management system)이 요구됨
- 본 논문에서는 MADRL 기반 새로운 항공 교통 서비스 관리 알고리즘(air transportation service management algorithm)을 제안함
- 승객에게 효율적인 항공 교통 서비스를 제공하기 위해 다중 UAM에 중앙 집중 교육 및 분산 실행(centralized training and distributed execution, CTDE)을 활용한 통신 네트워크(communication network, CommNet)를 기반으로 함
- 현실적인 항공 교통 네트워크를 구축하기 위해 실제 vertiport 맵과 UAM 사양(specification)을 채택함
By evaluating the performance of the proposed algorithm in data-intensive simulations, the results show that the proposed algorithm outperforms existing approaches in terms of air transportation service quality. Furthermore, there are no inferior UAMs by utilizing parameter sharing in CommNet and a centralized critic network in CTDE. Therefore, it can be confirmed that the research results in this paper can provide a promising solution for autonomous air transportation management systems in city-wide urban areas.
- 데이터 중심 시물레이션(data-intensive simulation)에서 제안된 알고리즘의 성능을 평가함으로써, 제안된 알고리즘이 항공 교통 서비스 품질 측면에서 기존의 접근 방식을 능가함
- CommNet의 매개 변수 공유와 CTDE의 중앙 집중 Critic Network를 활용하여 열등한 UAM이 없음
- 연구 결과는 도시 전체 지역의 자율적인 항공 교통 관리 시스템에 대한 유망한 솔루션을 제공할 수 있음
I. Introduction

Countless hours are squandered daily due to road congestion in numerous global metropolises. Inhabitants of cities like Los Angeles and Sydney experience an annual commuting duration equivalent to seven full working weeks, during which two weeks are consumed by traffic delays [2]. The resulting time inefficiency contributes to decelerated economic expansion, diminished productivity, and unwarranted carbon emissions.
- 수많은 대도시의 도로 정체로 인해 수많은 시간이 낭비
- LA, 시드니 같은 대도시 거주자는 연간 약 7주에 해당하는 full-time 근무 시간과 맞먹는 통근 시간을 겪음
- 이중 2주에 해당하는 시간은 교통 체증 때문임 → 시간 비효율성은 경제 확장 속도를 늦추고 생산성을 저하시키고, 불필요한 탄소 배출을 발생
To address this issue, expanding mobility from the horizontal plane to the vertical dimension is imperative. Vertical transportation modalities, such as urban-airmobility (UAM), promise to mitigate these pervasive urban dilemmas [3]. UAM has garnered considerable interest in contemporary times, owing to its capacity for mitigating traffic bottlenecks and facilitating effective transportation services [4]-[7]. At present, a multitude of companies worldwide are engaged in the development of UAMs to commercialize them, such as the Volocopter 2X by e-Volo GmbH, Neva AirQuadOne by Neva Aerospace, Boeing PAV by Aurora Flight Sciences, Joby S2 VTOL/ Cruise Configuration by Joby Aviation, and Opener Blackfly by Opener [8].
- 이러한 문제를 해결하려면 수평면에서 수직 차원으로 이동성을 확장해야 함
- UAM과 같은 수직 교통 방식은 도시 딜레마를 완화할 것, UAM은 교통 병목 현상을 완화, 효과적은 교통 서비스를 촉진 → 현대에 많은 관심을 받음
- 많은 기업이 UAM 상용화 개발에 참여 중
Nonetheless, there remains a need for more concrete evidence regarding the feasibility of air transportation in relation to the possibilities and demands, both in the presence and absence of autonomous vehicles. As for delivering telecommunications, cellular networks emerge as viable options, owing to their widespread accessibility and substantial capacity, particularly in urban environments [8]. Furthermore, the 5G standard offers services such as ultra-low latency reliable communications and vehicle-to-everyting (V2X) communication, which serve as intriguing components for constructing cellular-based drone operations [9], [10].
- 자율주행차의 유무와 관련해 항공 운송의 가능성과 수요에 대한 구체적인 근거가 필요
- 도시 환경에서 셀룰러 네트워크는 접근성과 큰 용량(capacity)으로 통신을 제공할 수 있는 실행 가능한 옵션
- 5G 표준(standard)는 초저지연, 신뢰가능한 통신과 vehicle-to-everything 통신과 같은 서비스 제공
- 따라서, 셀룰러 기반 드론 운영 구성이 가능
Next, from the perspective of feasibility in implementing pricing policies to convert existing transportation users to UAM users, the work in [11] used actual ground access transportation data collected from Incheon International Airport (ICN) and a multinomial logit model (MNL) to estimate the fare range for UAM services between Seoul Station and ICN. Assuming that UAM services can reduce travel time by 30-40 minutes compared to conventional ground taxis, the fare range was estimated to be between 96 and 108 US dollars. When comparing these estimated fares with those from expert institutions, it was demonstrated that such pricing policies are reasonable.
- 기존의 교통 사용자를 UAM 사용자로 전환하기 위한 가격 정책을 시행하는 데에 있어 실현 가능성 관점에서 인천국제공항(ICN)에서 수집된 실제 지상 교통 서비스와 다항 로짓 모델(multinomial logit model, MNL)을 사용하여 서울역과 인천국제공항 간 UAM 서비스의 요금 범위를 추정
- UAM 서비스가 기존 지상 택시에 비해 이동 시간을 30~40분을 줄일 수 있다고 가정, 요금 범위는 96~108달러(원화 128,000~144,000원)로 추정되었음 (전문 기관의 요금과 비교하여 가격 정책이 합리적임을 입증하였음)
→ 네이버 길찾기 기준 택시로 이동 시 60km 1시간 소요되며, 예상 요금 58,000~75,000원
Lastly, the work in [12] demonstrates that UAM aircraft presents a viable option for air transportation networks, offering significant advantages with respect to vehicle payload and certification risks. Although the required runway lengths for UAMs range from 100 to 300 feet, which may appear short, they are achievable with near-future technology. In fact, a 300 foot runway length can be easily attained for UAM aircraft even with current technology, making it feasible from an urban infrastructure development perspective as well.
- UAM 항공기가 항공 운송 네트워크(air transportation networks)에 실현 가능한 옵션으로 제공되어 차량 경비 부담(vehicle payload) 및 certification risks와 관련하여 상당한 이점을 제공
- UAM에 필요한 활주로 길이는 100~300ft(약 30~90m)로, 짧아보이지만 미래 기술로 충분히 달성 가능 (실제 UAM 항공기의 경우 현재 기술로 300ft 활주로 길이를 쉽게 달성할 수 있었음) → 도시 인프라 개발 관점에서 충분히 가능함
The primary advantage of UAM compared to traditional ground-based transportation lies in its potential to significantly reduce overall travel durations. Additionally, UAMs address the issue of air contamination resulting from greenhouse gas emissions (GGE), which adversely affects the well-being of proximate inhabitants [13]. This is achievable because UAM operates on the basis of an eco-friendly electric propulsion system [14].
- 지상 운송 수단에 비해 UAM은 총 이동 시간을 크게 줄일 수 있다는 주요 이점
- UAM이 전기 추진 시스템을 기반으로 작동하므로 온실 가스 배출로 인한 대기 오염 문제를 해결함
Despite the potential benefits, the integration of UAMs within prevailing transportation frameworks encounters a multitude of difficulties, such as the synchronization and collaboration between multiple UAMs [4]. Therefore, this paper puts forth a novel multi-agent deep reinforcement learning (MADRL) strategy with the objective of devising a trustworthy and effective aerial transportation system. Within the suggested MADRL-focused methodology, a communication network (CommNet) [15] is employed, incorporating centralized training and decentralized execution (CTDE) [16].
- 기존의 운송 프레임워크 내에서 UAM을 통합하면 여러 UAM간의 동기화 및 협업과 같은 다양한 어려움에 직면함
- 본 논문에서는 신뢰할 수 있고(trustworthy) 효과적인(effective) 항공 운송 시스템을 설계하기 위한 목적으로, 새로운 MADRL Strategy를 제안
- 제안된 MADRL-focused 방법론 내에서 CTDE(중앙 집중 훈련 및 분산 실행) + CommNet(communication network)이 사용됨
CommNet facilitates intercommunication among multi-UAM to achieve coordination, while CTDE employs a centralized critic to enhance the training efficacy of all actors commensurate with the agent's policy. The proposed MADRL-centric method tackles numerous obstacles in UAM functioning, including collision circumvention, trajectory formulation, and passenger routing. The employment of a multi-agent framework facilitates optimized utilization of airspace and resources, concurrently guaranteeing the security of passengers and UAM vehicles.
- CommNet은 coordination을 달성하기 위해 다중 UAM간의 상호 통신을 용이하게 함
- CTDE는 agent의 policy에 맞는 모든 actor의 학습 효과를 향상하기 위해 centralized critic을 사용
- 제안된 MADRL 중심 방법론은 충돌 우회, 궤적 공식화 등 승객 라우팅을 포함하여 UAM 기능의 수많은 장애물을 해결
- Multi-Agent 프레임워크를 사용하면 영공(airspace)과 자원(resources)을 최적화하여 승객과 UAM의 안전을 동시에 보장할 수 있음
This paper evaluates the suggested MADRL-centric approach using data-driven simulations within realistic environment settings. A diverse set of findings demonstrates that the proposed technique surpasses current methodologies with respect to efficiency while maintaining safety. This proposed strategy holds the potential to substantially advance the development of a resilient and effective air transportation framework.
본 논문에서는 실제 환경 설정 내에서 데이터 기반 시뮬레이션을 사용하여 제안된 MADRL 중심 접근 방식을 평가합니다. 다양한 결과를 통해 제안된 기술이 안전을 유지하면서 효율성 측면에서 현재 방법론을 능가한다는 것을 보여줍니다. 제안된 전략은 탄력적이고 효과적인 항공 운송 프레임워크 개발을 크게 발전시킬 수 있는 잠재력을 가지고 있습니다.
- 본 논문에서는 현실의 환경 설정(realistic environment settings) 내에서 data-driven 시뮬레이션을 사용하여 제안된 MADRL 중심 접근 방식을 평가
- 다양한 결과를 통해 제안된 방법이 안전을 유지하며 효율성 측면에서 현재 방법론을 능가한다는 것을 보여줌
- 제안된 전략은 탄력적이고, 효과적인 항공 운송 프레임워크 개발을 크게 발전시킬 수 있는 잠재력을 갖고 있음
I-A. Contributions
The main contributions of this work are as follows.
Multi-UAM Cooperation and Coordination using MADRL. This paper utilizes a novel CommNet/CTDE-based MADRL strategy to manage air transportation networks efficiently under the concept of the cooperation and coordination of multiple UAMs. This advanced training structure helps multiple UAMs perform given common tasks more efficiently without explicit central coordination rules after the policy training phase.
- 여러 UAM의 협력 및 조정 개념으로 항공 교통망을 효율적으로 관리하기 위해 새로운 CommNet/CTDE 기반 MADRL 전략을 활용
- 이러한 Advanced 학습 구조는 Policy 학습 단계 이후 명시적인 중앙 조정(explicit central coordination) 없이 여러 UAM이 주어진 공통 작업을 보다 효율적으로 수행할 수 있도록 도와줌
Realistic City-Wide Environment Design and Performance Evaluation. A vertiport map and UAM model are designed with the actual reference model to construct a realistic autonomous air transportation system. The energy charging/discharging model is accurately modeled with the specifications of the adopted UAM model, and even the passenger boarding and alighting system are designed in detail. Therefore, the justification of the proposed air transportation system becomes more potent than when an arbitrary system is assumed. Furthermore, in order to validate the MADRL supremacy of the proposed algorithm, data-intensive performance evaluation is conducted with the latest DRL algorithms from various aspects. Furthermore, this paper analyzes the results in detail with the subdivided groups according to the learning strategy.
- Vertiport 맵과 UAM 모델을 실제 참조 모델(actual reference model)로 설계하여 현실적인 자율 항공 운송 시스템을 구축
- 에너지 충전 및 방전 모델은 채택된 UAM 모델의 사양으로 정확하게 모델링(accurately modeled)됨
- 승객 승하차 시스템은 상세하게 설계됨(designed in detail)
- 제안된 항공 운수 시스템의 정당성(justification)은 임의의 시스템(arbitrary system)을 가정할 때 강력함
- 제안된 알고리즘 내 MADRL의 우월성(supremacy)을 검증하기 위해 다양한 측면에서 최신 DRL 알고리즘으로 데이터 집약적(data-intensive) 성능 평가를 수행, 학습 전략에 따라 세분화된 그룹으로 결과를 상세히 분석함
I-B. Organization
The remainder of the paper is structured as follows. Sec. II reviews related work in air transportation management systems and Sec. III explains the system model considered in this paper. Sec. IV presents the proposed management algorithm for efficient autonomous air transportation networks employing CommNet/CTDE-based MADRL. Sec. V demonstrates the performance of the proposed algorithm via various data-intensive evaluations. Finally, Sec. VI concludes this paper.
- Section II. 관련된 항공 운송 관리 시스템 연구 작업 검토 (Related Work)
- Section III. 제안된 시스템 모델을 설명
- Section IV. CommNet/CTDE 기반의 MADRL을 적용한 효율적인 Autonomous Air Transportation Network를 위한 제안된 관리 알고리즘(Management Algorithm)을 제시
- Section V. 데이터 집약적(Data-Intensive) 평가를 통해 알고리즘의 성능 평가
- Section VI. 결론(conclusion)
II. Related Work
Self-governing vehicular have increasingly garnered interest from scholarly and commercial domains due to their potential to address enduring issues in transportation, such as safety enhancement, traffic alleviation, energy conservation, and other related concerns [17]-[19]. Advanced computational methodologies, such as deep learning (DL) and machine learning (ML) approaches, are employed to augment the efficacy of autonomous mobility systems [20], [21].
- 자율 주행 차량은 안전 향상, 트래픽 완화, 에너지 절약 및 기타 관련 문제와 같은 교통 수단의 지속적인 문제를 해결할 수 있는 잠재력으로 인해 점점 더 많은 학자 및 상업 영역에서 관심을 얻고 있음
- 자율 이동 시스템의 효율성을 높이기 위해 딥러닝(DL) 및 머신 러닝(ML) 접근 방식과 같은 고급 계산 방법론이 사용됨
In urban settings, traffic data exhibit consistent characteristics concerning location and time within logistical systems. Consequently, learning-based algorithms demonstrate resilience, as they are capable of capturing the recurrence of similar patterns occurring at identical locations and times.
- 도시 환경에서 트래픽 데이터는 물류 시스템 내에서 위치 및 시간과 관련하여 일관된 특성을 나타냄
- 결과적으로 학습 기반 알고리즘은 동일한 위치 및 시간에서 발생하는 유사한 패턴의 재발을 포착할 수 있기 때문에 복원력(resilience)을 보여줌
A joint K-mean clustering and Gaussian mixture model-based expectation maximization [22] and the attention mechanism are utilized for trajectory optimization [23]. However, the strategies utilized in the aforementioned traditional optimization and rule-based research, including those in [24], [25] that suggest methods for optimizing trajectories in autonomous aerial vehicles, predominantly concentrate on centralized optimization concerns.
- 공동 K-Means 클러스터링 및 Gaussian 혼합 모델 기반 기대 극대화(expectation maximization)와 Attention 메커니즘이 궤적 최적화(trajectory optimization)에 사용됨
- 그러나 자율 항공기에서 궤적을 최적화(optimization trajectories)하는 방법을 제안하는 [24], [25]를 포함하여 앞서 언급한 전통적인 최적화 및 규칙 기반 연구에서 사용된 전략은 주로 중앙 집중식 최적화 문제(centralized optimization concerns)에 중점을 둠
This limited scope results in hindrances when attempting to provide real-time solutions for complex, dynamic, interrelated, and widespread transportation systems [26]. Furthermore, their approaches in massive environment may cause pseudo-polynomial computational complexity based on dynamic programming [27].
- 이러한 제한된 범위(limited scope)는 복잡하고 역동적이며 상호 관련(interrelated)이 있으며 광범위한 교통 시스템에 대한 실시간 솔루션을 제공하려고 시도할 때 방해됨
- 또한 대규모(massive) 환경에서 이러한 접근 방식은 dynamic programming을 기반으로 한 의사 다항식 계산 복잡성(pseudo-polynomial computational complexity)을 유발할 수 있음
In the context of deep reinforcement learning (DRL) algorithms, the computational complexity does not exhibit a general pseudo-polynomial time complexity; instead, it primarily depends on factors such as the size of the state space and the size of the action space. In addition, imitation learning with advanced sensors is also employed for smart cruise control and lane-keeping systems [28]. However, imitation learning necessitates the provision of expert demonstrations and may suffer from covariate shift or suboptimal performance due to the limited exploration.
- DRL 알고리즘의 경우 계산 복잡성이 일반적인 의사 다항식 시간 복잡성을 나타내지 않으며 주로 상태 공간의 크기와 행동 공간의 크기와 같은 요인에 따라 달라짐
- 고급 센서(advanced sensor)를 사용한 모방 학습(imitation learning)이 스마트 크루즈 컨트롤 및 차선 유지 시스템에도 사용됨
- 모방 학습은 전문가 시연(expert demonstrations)을 제공해야 하며 제한된 탐색(limited exploration)으로 인해 공변량 이동(covariate shift) 또는 차선 성능(suboptimal performance)의 문제를 겪을 수 있음
Besides, among various DL and ML algorithms, DRL techniques have demonstrated the most effective performance by adaptively executing sequential decision-making processes in dynamic autonomous driving environments [20], [29]. Furthermore, the scalability of RL allows for the application of MADRL to govern the operation of multiple mobilities.
- 다양한 DL, ML 알고리즘 중 DRL은 동적 자율 주행 환경에서 순차적 의사 결정 프로세스(sequential decision-making processes)를 적응적으로 실행(adaptively executing)하여 가장 효과적인 성능을 입증하였음
- 또한 RL의 확장성(scalability)을 통해 MADRL을 적용하여 여러 mobility의 작동을 제어할 수 있음
Among MADRL algorithms, the Q-Mix algorithm incorporates a comprehensive action-value function derived from the amalgamation of individual agents' action-value functions [30]. This algorithm is applied for the trajectory optimization of multiple electric vertical takeoff and landings (eVTOLs) [3] in the context of aerial drone-taxi applications [31].
- MADRL 알고리즘 중 Q-Mix 알고리즘은 개별 agent의 행동-가치 함수(action-value function)의 병합(amalgamation)에서 파생된(derived) 포괄적인(comprehensive) 행동-가치 함수를 통합(incorporate)함
- Q-Mix 알고리즘은 항공 드론 택시 애플리케이션의 맥락에서 여러 eVTOL의 궤적 최적화에 적용
In addition, there are MADRL algorithms founded upon their inherent communication protocols, which utilize a neural network structure designed to facilitate inter-agent data exchange. Examples of these algorithms include differentiable inter-agent learning (DIAL) [32], bilateral complementary network (BiCNet) [33], and CommNet. DIAL-based agents use differentiable communication channels within their neural networks to learn cooperative strategies through end-to-end back propagation, leading to improved coordination and cooperation among agents in complex, dynamic environments. Next, BiCNet introduces a cutting-edge approach to address complex coordination challenges in MADRL by utilizing a twin neural network architecture, which enables agents to learn complementary policies collaboratively.
- 또한, agent 간의 데이터 교환을 용이하게 하도록 설계된 신경망 구조를 활용하는 고유한 통신 프로토콜을 기반으로 하는 MADRL 알고리즘이 있음 → DIAL(Differentiable Inter-Agent Learning), BiCNet(Bilateral Complementary Network), CommNet 등이 있음
- DIAL 기반 agent는 신경망 내에서 차별화된 통신 채널(differentiable communication channels)을 사용하여 end-to-end 역전파를 통해 협력 전략을 학습함 → 복잡하고 동적인 환경에서 agent 간의 조정 및 협력을 향상할 수 있음
- BiCNet은 agent가 상호 보완적인 정책을 협력적으로 학습할 수 있는 쌍둥이 신경망 아키텍처(twin neural network architecture)를 활용하여 MADRL의 복잡한 조정 문제(complex coordination challenge)를 해결하는 최첨단 접근 방식(cutting-edge approach)을 도입
다음으로, BiCNet은 에이전트가 상호 보완적인 정책을 협력적으로 학습할 수 있는 쌍둥이 신경망 아키텍처를 활용하여 MADRL의 복잡한 조정 문제를 해결하는 최첨단 접근 방식을 도입합니다.
Finally, as elucidated in [15], agents employing the CommNet framework acquire communication capabilities in tandem with a unified, centralized single deep neural network to process local observations for multiple agents. Subsequently, each agent's decisions are influenced by its individual observations and the mean of other agents' observations [34]. The CommNet architecture is extensively applied in diverse multi-agent systems in a distributed manner, such as management for electric vehicle charging station [35], charging scheduling in UAV networks [36], and autonomous surveillance system [37].
- CommNet 프레임워크를 사용하는 agent는 여러 agent에 대한 local observation을 처리하기 위해 통합(unified)되고 중앙집중된(centralized) 단일 심층신경망(single DNN)과 함께 통신 기능(communication capabilities)을 동시에 얻음
- 이후, 각 agent의 결정(decisions)은 개별 관찰(individual observation)과 다른 agent의 관찰 평균(mean of agents’ observation)에 영향을 받음
- CommNet 아키텍처는 전기차 충전소에 대한 관리, UAV 네트워크에서의 충전 스케줄링, 자율 감시 시스템(autonomous surveillance system)과 같은 분산 방식(distributed manner)으로 다양한 멀티 에이전트 시스템에 광범위하게 적용됨
While the previous study in [1] also suggests the CommNet centric MADRL algorithm for establishing an autonomous multi-UAM network, several distinctions exist between the present and aforementioned works. Primarily, the algorithm proposed herein further utilizes centralized critic, in contrast to only focusing on CommNet in [1]. Moreover, this work evaluates the performance of the proposed MADRL algorithm while considering various communication statuses compared to previous studies in [1]. Additionally, an additional inference step is conducted to validate the effectiveness of the learned policy.
- [1]의 이전 연구에서도 자율 다중 UAM 네트워크를 구축하기 위한 CommNet centric MADRL 알고리즘을 제안하고 있지만, 현재 작업과 앞서 언급한 작업 사이에는 몇 가지 차이점이 있음
- 기본적으로 [1]에서 CommNet에만 초점을 맞춘 것과 달리 본 연구에서 제안된 알고리즘은 중앙 집중식 비판(centralized critic)을 더 활용
- 또한 본 연구에서는 [1]의 이전 연구와 비교하여 다양한 통신 상태(various communication statuses)를 고려하면서 제안된 MADRL 알고리즘의 성능을 평가
- 또한, 학습된 policy(정책)의 효과(effectiveness)를 검증하기 위해 추가 추론 단계(additional inference step)를 수행
III. Realistic City-Wide Autonomous Air Transportation System Design
This paper constructs a realistic air transportation environment and UAM model based on actual vertiports and aircraft. This realistic design suggests a direction in which UAM can be realized in various bustling metropolitan areas, including Dallas, Texas, and Bedtown Frisco, USA.
- 본 논문에서는 실제 vertiport와 항공기를 기반으로 현실적인 항공 운송 환경과 UAM 모델을 구축
- 이러한 현실적인 설계는 Texas, Dallas, Bedtown Frisco를 포함한 다양한 번잡한 대도시 지역에서 UAM이 실현될 수 있는 방향을 제시
III-A. Realistic Air Transportation Environment

Uber will provide UAM service to various metropolitan areas such as Sao Paulo and Los Angeles within 10 years [2]. Dallas, Texas, a central US metropolitan area, is no exception. Uber Air will begin commercial operations in Dallas in 2023, making it the first city to provide flights. The vertiport environment with the highest possibility of realization is Dallas, Texas. The actual background of the vertiport map used in the experiment corresponds to a movement zone connecting Downtown Dallas, Texas, USA, and Bedtown Frisco to the north. The actual detailed vertiport map information is illustrated in Fig. 2 [38]. Fig. 2 shows the central transportation network of the United States, which connects downtown Dallas, Texas, with Frisco, centered on Dallas Fort Worth International(DFW) Airport. In this transportation network, Uber will build a total of five vertiports at DFW AIRPORT (A), FORT WORTH (B), DOWNTOWN DALLAS (C), LOVE FIELD (D), and FRISCO (E). The black number means the distance between vertiports. The length of the bar on the top left represents about 10 km in real space. The scale is 1: 1,230, 000, thus 1 cm in Fig. 2 corresponds to 12.3 km.
- 우버(Uber)는 10년 이내 상파울루, LA 등 다양한 대도시에 UAM 서비스를 제공할 것
- 우버 에어(Uber Air)는 2023년부터 텍사스주 댈러스(Dallas)에서 상업 운항을 시작해 가장 먼저 항공편을 제공하는 도시가 될 것임
- 따라서, 가장 실현 가능성이 높은 vertiport 환경은 텍사스 댈러스임. 실험에 사용된 vertiport 맵의 실제 배경은 미국 댈러스 Downtown 북쪽의 Bedtown Frisco를 연결하는 이동 구역에 해당 (상세한 실제 vertiport 맵 정보는 그림 2와 같음)
- 그림 2는 댈러스 포트워스 국제공항(DFW)을 중심으로 텍사스 댈러스 Downtown과 Frisco를 연결하는 미국의 중심 교통망을 보여주고 있음
- 해당 교통망에서 우버는 DFW AIRPORT (A), FORT WARS (B), DOWNTOWN DALLAS (C), LOVE FIELD (D), FRISCO (E)에 총 5개의 vertiport를 구축하게 됨
- 검은색 글씨 숫자는 각 포트 사이 거리임, 지도의 축척(scale)는 1:1,230,000 (지도에서 1cm = 12.3km)
III-B. Realistic UAM Model
It is vital to take the energy consumption/remains of UAM devices into account because they are energy-constrained and power-hungry [4], [39]. In contrast to the aircraft powered by internal combustion engines, which produce energy by burning fossil fuels, UAM is an electrified aircraft that relies on batteries. Accordingly, the energy model of UAM can be represented by aerodynamic power calculations independent to the specific fuel consumption (SFC). UAM's hovering power expenditure $P_h$ when take-off or landing with passengers can be mathematically expressed as follows [40],
- UAM은 에너지 제약을 받고 전력이 부족하므로 에너지 소비/잔량을 고려해야 함 (UAM은 내연 기관을 사용하지 않고 전기 기반의 배터리를 사용)
- 따라서 UAM의 에너지 모델은 특정 연료 소비(specific fuel consumption, SFC)에 독립적인 공기역학적 전력 계산(aerodynamic power calculation)으로 나타낼 수 있음.
- 승객을 동반한 이착륙 시 지출되는 $P_h$는 수학적으로 과 같이 나타낼 수 있음
- 승객 탑승 후 이착륙 시 UAM의 호버링 전력 지출(hovering power expenditure) $P_h$는 수학적으로 아래 식과 같이 나타낼 수 있음

where $C_d$ is the drag coefficient, which is a dimensionless coefficient that quantifies the drag force of a body in a fluid, $\rho$ is the density of air that decreases exponentially with altitude, and $s$ is the rotor solidity that means the ratio of the rotor blade area to the rotor disk area. In addition, $A$, $\Omega$, $R$, $W$ stand for the rotor disc area, blade angular velocity, rotor radius, and total weight considering passenger payload, respectively. $k$ is an induced drag coefficient that is inversely proportional to the efficiency factor $(e)$ and aspect ratio $(AR)$. UAM must rotate the rotor to overcome the drag increased by the induced drag, so k must be considered in (1). When a UAM carrying a passenger rises to an altitude of 600m by eVTOL and propels forward, the force on the x-axis is added.
- $C_d$: 유체 내 물체의 항력을 정량화(quantifies)하는 무차원 계수(dimensionless coefficient)인 항력 계수(drag force)
- $\rho$: 고도(altitude)에 따라 지수함수적으로 감소하는 대기 밀도(density of air)
- $s$: 로터 디스크 면적(rotor disk area)에 대한 로터 블레이드 면적(rotor blade area)의 비율을 의미하는 로터 견고성(rotor solidity)
- $A$: 로터 디스크 면적(rotor disk area)
- $\Omega$: 블레이드 각속도(blade angular velocity)
- $R$: 로터 반지름(rotor radius)
- $W$: 승객 payload를 고려한 총 중량(total weight)
- $k$는 효율 계수(efficiency factor)$(e)$ 및 종횡비(aspect ratio)$(AR)$에 반비례하는 유도 항력 계수(induced drag coefficient), UAM은 유도 항력(induced drag)에 의해 증가된 항력을 극복(overcome)하기 위해 로터를 회전시켜야 하므로 (1)에서 $k$를 고려해야 함
여기서, 견고성 비율(solidity ratio)란?

- $N$: number of blades
- $c$: mean aerodynamic chord length of blade
- $R$: Radius of the disk
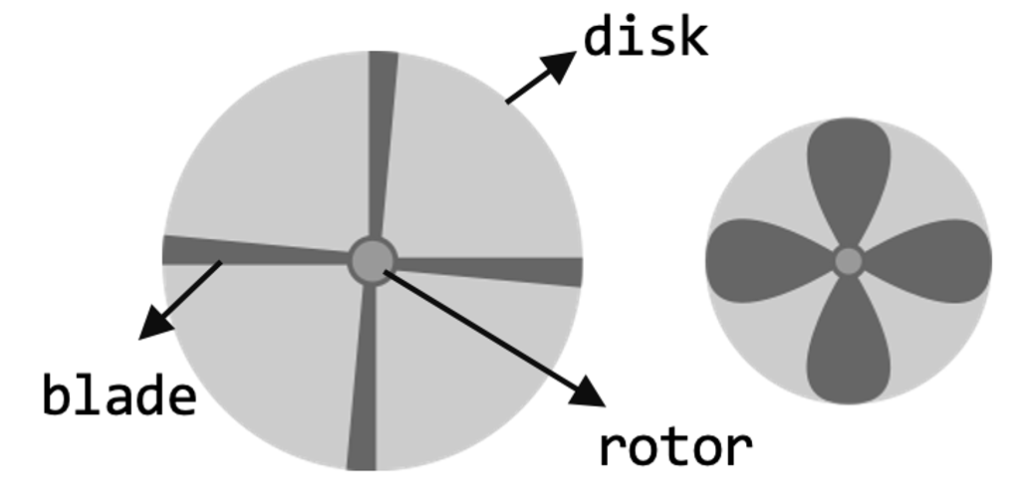
A crude idea of what a rotor or propeller geometry looks like can be obtained from the rotor solidity ratio. Rotors with stubbier and/or a larger number of blades have a larger solidity ratio since they cover a larger fraction of the rotor disk. Rotorcraft like helicopters typically use blades with very low solidity ratios compared to fixed-wing and marine propellers.
- 로터 또는 프로펠러 기하학이 어떻게 생겼는지에 대한 대략적인 아이디어는 로터 견고성 비율(solidity ratio)에서 얻을 수 있음
- 더 짧거나 더 많은 수의 블레이드를 가진 로터는 로터 디스크의 더 많은 부분을 덮기 때문에 더 큰 견고성 비율을 가짐
- 헬리콥터와 같은 회전익 항공기는 일반적으로 고정 날개 및 해상 프로펠러에 비해 견고성이 매우 낮은 블레이드를 사용함
Thus, the propulsion power consumption $P_p$ must be considered. Here, the energy expenditure during a round trip or propulsion can be mathematically expressed as follows [41],
[41] Y. Zeng and R. Zhang, “Energy-efficient UAV communication with trajectory optimization,” IEEE Transactions on Wireless Communications, vol. 16, no. 6, pp. 3747–3760, June 2017.
- 승객을 태운 UAM이 eVTOL에 의해 600m 고도까지 상승하여 전방으로 추진하면 x축에 대한 힘이 추가됨, 따라서 추진 동력 소비량(propulsion power consumption) $P_p$를 고려해야 함
- 여기서 왕복/추진 중 에너지 지출(the energy expenditure during a round trip or propulsion)은 수학적으로 다음과 같이 나타낼 수 있음


where $v$ is the cruising flying speed of UAM at which UAM reaches an altitude of 600m and cruises after picking up passengers. $v_0$ is mean rotor-induced velocity which is the flow's average speed as caused by the wing tip vortex. $U_{tip}$ is tip speed of the rotor blade and $d_0$ is fuselage drag ratio. The values of the aerodynamic parameters used in (1) and (2) are for JOBY AVIATION's S4 and are displayed in Table I [42].
- $v$: UAM이 600m 고도에 도달하여 승객을 태운 후 순항하는 UAM의 순항 비행 속도(cruising flying speed)
- $v_0$: 날개 끝(wing tip) 와류(vortex)에 의해 발생하는 흐름의 평균 속도(flow’s average speed)인 평균 rotor-induced(유도) 속도
- $U_{tip}$: rotor blade의 끝(tip) 속도
- $d_0$: 동체 항력비(fuselage drag ratio)
- (1)과 (2)에 사용된 공기역학적 매개변수의 값은 JOBY AIVAL의 S4에 대한 것이며 표 I [42]에 나와 있음

According to Joby Aviation's analyst day presentation [42], S4 ascends to an altitude of 600m in around 30 seconds after carrying passengers. Since the turnaround time is about 6 minutes, UAM landing on a vertiport must unload passengers and recharge its battery as much as possible in the meantime. Here, the realistic actual charging time is only 5 minutes, excluding the time to turn on/off the electric engine and plug in/out the charging cap. However, S4 can charge its battery quickly via a charger plugged directly behind the inboard tilt electric motor nacelle. It is equipped with four battery packs, two on both sides of the main wing inboard and the others in the nacelle at the rear of the main wing inboard electric motor. To charge each battery with 30 kWh in 5 minutes, the charger's supply power must be at least 360 kW. Under this condition, S4's current rate (C-rate) indicating the battery charge/discharge rate becomes 2.4 per hour when a 150 kWh battery is charged with a 360 kW charger. Finally, the state of charge (SOC) that is the time to charge the battery to 100% takes 25 minutes, and S4 can charge 20% of the total battery capacity per journey. Table Il summarizes a detailed description of the battery specifications.
- Joby Aviation의 analyst day 발표[42]에 따르면, S4는 승객을 태운 후 약 30초 만에 600m 고도까지 상승함. turnaround time은 약 6분이므로, 그 동안 vertiport에 착륙하는 UAM은 승객을 내리고 배터리를 최대한 충전해야 함
- 현실적인 실제 충전 시간은 전기 엔진의 온/오프와 충전 캡의 플러그인/아웃 시간을 제외하고 5분에 불과함, 그러나 S4는 인보드 틸트 전기 모터 나셀(inboard tilt electric motor nacelle)의 바로 뒤에 플러그인된 충전기를 통해 배터리를 빠르게 충전할 수 있음
- 이것은 4개의 배터리 팩이 장착되어 있는데, 두 개는 메인 윙 인보드 양쪽에 있고 다른 하나는 메인 윙 인보드 전기 모터의 후면에 있는 나셀에 있습니다.
- 각 배터리를 5분 안에 30kWh로 충전하려면 충전기의 공급 전력이 360kW 이상이어야 합니다. 이 조건에서, 150kWh 배터리를 360kW 충전기로 충전했을 때 배터리 충방전 속도를 나타내는 S4의 전류율(C-rate)은 시간당 2.4가 됩니다.
- 마지막으로, 배터리를 100%로 충전하는 시간인 충전 상태(SOC)는 25분이 소요되며, S4는 주행당 총 배터리 용량의 20%를 충전할 수 있습니다. 표 Il은 배터리 사양에 대한 자세한 설명을 요약한 것입니다.
Joby Aviation의 S4 모델에 대한 자세한 정보는 아래 링크를 참고
Joby Aviation | Joby
A Better Way to Move
www.jobyaviation.com
https://aviationweek.com/aerospace/advanced-air-mobility/joby-aviation-s4-program
Joby Aviation S4 Program | Aviation Week Network
https://aviationweek.com/themes/custom/particle/dist/app-drupal/assets/awn-logo.svg Skip to main content Apple app store ID 6447645195 Apple app name apple-itunes-app App argument URL https://shownews.aviationweek.com
aviationweek.com

Joby Aviation사의 S4 모델의 Specification
| Aircraft Type | Tiltrotor eVTOL |
| Seats | Pilot + 4 |
| MTOW | 2,177 kg/4,800 lbs. |
| Payload | Unknown |
| Length | 6.4 m/21 ft. |
| Wingspan | 11.8. m/39 ft. |
| Landing Gear | Tricycle-wheeled retractable landing gear. |
| Cruising Altitude | 4,572m/15,000 ft |
| Cruising Speed | 322 km/h/200 mph |
| Range | 241km/150 miles |
| Endurance | Variable |
| Entry into Service | 2025 |
| Suppliers | Toray Advanced Composites to supply carbon fibre composite materials. Garmin to supply integrated flight deck. Toyota to supply key powertrain and actuation components. GKN to supply thermoplastic flight control surfaces. |
| Structure | Carbon fibre composite materials and features a high wing and V-shaped tail. |
| Propulsion | Six electric motors, four on wing and two on V-tail. Distributed electric motors are in-house built and include dual redundant inverters, variable propeller pitch, nacelle tilting/cooling and dual windings. |
| Power/Energy Storage | Four liquid cooled lithium ion battery packs, with an energy density of 300 Wh/kg. |
| Flight Controls | Garmin fly-by-wire integrated flight deck. |
| Takeoff & Landing | VTOL, can land conventionally in emergency situations. |
| Autonomy | None |
| Collision Avoidance | Unknown |
| IFR Compliant | Unknown |
| Transponder | Unknown |
| ADS-B | Unknown |
| RNAV/RNP | Unknown |
| GNSS & GBAS | Unknown |
| Communication | Unknown |
| Safety | |
| Overall Safety | Redundant control surfaces, distributed electric propulsion (aircraft can land despite 1-2 motor failures). |
| Passenger Safety | Unknown |
| Ground Safety | Unknown |
| Flight Emergency | Can land conventionally in emergency situations. |
| Certification | |
| Aircraft | FAA; also seeking UK CAA and Japan Civil Aviation Bureau. |
| Certification Type | FAA Part 21.17(b) |
| Aircraft Cert Schedule | Target 2024 |
| Flight Tests | Marina, CA |
| Flight Operations | FAA Part 135 Air Taxi Operator |
| Pilot License | Yes |
| Vertiport Locations | Los Angeles, San Fransisco, Miami, New York. |
| Vertiport Design/Build | Unknown |
IV. Algorithm Design
IV-A. RL Formulation for UAM Networks
In order to consider the physical capabilities of UAM, this paper formulates UAM networks as a decentralized partially observable MDP (Dec-POMDP) [43], [44]. According to the nature of RL-based algorithms, each UAM with Dec-POMDP can sequentially make action decisions founded on partial environmental information. The considering reference air transportation model consists of $J$, $N$, and $Ξ$ numbers of UAMs, vertiports, and passengers, respectively. Thus, the sets of UAMs, vertiports, and passengers are defined as $∀u_j \in U$ where $U ≜ \{u_1,··· ,u_j,··· ,u_J\}$, $∀ρ_ξ \in G$ where $G \in \{ρ_1,··· ,ρ_ξ,··· ,ρ_Ξ\}$, and $∀ν_n \in V$ where $V∈\{ν_1,···,ν_n,···,ν_N\}$. Here, the air transportation service provided by UAMs in this paper can be defined as the passenger delivery using UAM from one vertiport to the other target vertiport.
- UAM의 물리적 능력을 고려하기 위해 본 논문은 UAM 네트워크를 분산 부분 관찰 가능한(Decentralized Partially Observable) MDP(Dec-POMDP)로 공식화
- RL 기반 알고리즘의 특성에 따라 Dec-POMDP가 적용된 각 UAM은 부분 환경 정보(partial environment information)를 기반으로 순차적(sequentially)으로 action decision을 내릴 수 있음
- 고려된 참조 항공 운송 모델(reference air transportation model)은 각각 UAM, vertiport 및 승객의 $J$, $N$ 및 $Ξ$ 번호로 구성됨
- UAM 집합: $∀u_j \in \mathcal{U}$, $\mathcal{U} ≜ \{u_1,··· ,u_j,··· ,u_J\}$ (UAM 수 $J$)
- 승객 집합: $∀ϱ_ξ \in \mathcal{G}$, $\mathcal{G} \in \{ϱ_1,··· ,ϱ_ξ,··· ,ϱ_Ξ\}$ (승객 수 $Ξ$)
- vertiport 집합: $∀ν_n \in \mathcal{V}$, $\mathcal{V}∈\{ν_1,···,ν_n,···,ν_N\}$ (vertiport 개수 $N$)
- 하나의 vertiport에서 다른 target vertiport까지 UAM을 사용한 승객 운송으로 정의할 수 있음
The POMDP of the proposed air transportation networks with $J$ UAMs can be modeled as $⟨J,\mathcal{S},\mathcal{O},\mathcal{A},\mathcal{R},\mathcal{P},\mathcal{Z},γ⟩$ where $s ∈ \mathcal{S}$ is a set of ground truth states. Next, $o_j ∈ \mathcal{O}_j$ and $a_j ∈ \mathcal{A}_j$ stand for a set of $j$-th UAM’s observations and actions, respectively. Note that these two sets can be jointly denoted as $\mathcal{O}_j ⊂ \mathcal{O}$ and $\mathcal{A}_j ⊂ \mathcal{A}$. At every time step, each UAM gets reward $r_j$ with reward function $\mathcal{R}(s, a, s')$ by selecting joint action a while observing joint observation information $o$ based on conditional observation probability $\mathcal{Z}(s',a,o) = \mathcal{S}×\mathcal{A} → \mathcal{O}$. Then, the global state $s$ is transited to the next state $s'$ with state transition probability function $\mathcal{P}(s'|s,a) = \mathcal{S}×\mathcal{A}×\mathcal{S} → \mathcal{S}$. Lastly, $γ$ is a discount factor that weights current rewards versus future rewards. The below subsections materialize the MDP delineating observation, state, action, reward, and objective of the proposed UAM networks via mathematical description.
- $J$개의 UAM이 있는 제안된 항공 교통 네트워크(air transportation networks)의 POMDP(Partially Observable MDP)는 $⟨J,\mathcal{S},\mathcal{O},\mathcal{A},\mathcal{R},\mathcal{P},\mathcal{Z},γ⟩$로 모델링 가능
- $s ∈ \mathcal{S}$: ground truth state 집합
- $o_j ∈ \mathcal{O}_j$: $j$번째 UAM의 observation 집합, $\mathcal{O}_j ⊂ \mathcal{O}$
- $a_j ∈ \mathcal{A}_j$: $j$번째 UAM의 action 집합, $\mathcal{A}_j ⊂ \mathcal{A}$
- 매 time step마다, 각 UAM은 보상 함수 $\mathcal{R}(s,a,s')$에 따라 보상(reward) $r_j$를 받음, joint observation information $o$로 선택된 joint action $a$에 기반한 조건부 observation 확률 $\mathcal{Z}(s',a,o) = \mathcal{S}×\mathcal{A} → \mathcal{O}$에 따름
- Global State(전역 상태) $s$는 상태 전이 확률 함수(state transition probability function) $\mathcal{P}(s'|s,a) = \mathcal{S}×\mathcal{A}×\mathcal{S} → \mathcal{S}$로 다음 state $s'$로 전환
- $γ$: discount factor
- 아래 섹션은 수학적 설명을 통해 제안된 UAM 네트워크의 observation, state, action, reward 및 objective(목적)를 설명하는 MDP를 구체화합니다.
1) Observation: Due to the physical limitation of the considered UAM model, every UAM can recognize other UAMs or vertiports within its coverage. Here, the eyesight of the $j$-th UAM is dependent on its absolute position denoted as $p_j \in \{x_j , y_j , z_j \}$ corresponding to Cartesian coordinates. The $j$-th agent can recognize distances with other UAMs and vertiports in its observation scope $D_{th}$, which information can be mathematically represented as follows,
- 고려된 UAM 모델의 물리적 한계로 인하여 모든 UAM은 범위(coverage) 내에서 또 다른 UAM과 vertiport를 인식(recognize)할 수 있음
- $j$번째 UAM의 시력(eyesight)은 데카르트 좌표(Cartesian coordinates)에 해당하는 $p_j$, $p_j \in \{x_j, y_j, z_j \}$로 표시되는 절대 위치(absolute position)에 따라 달라짐
- j번째 agent는 관찰 범위(observation scope) $D_{th}$에서 다른 UAM과 vertiport와의 거리를 인식할 수 있으며 다음과 같이 나타냄

→ $d(u_j, u_{j'})$: UAM $j$와 UAM $j'$간의 거리, $d(u_j, ν_{n'})$: UAM $j$와 vertiport $n'$간의 거리
관찰 범위 $D_{th}$ 밖에 있다면 $-1$, 범위 내에 있다면 거리 $d$
where $d(·)$ and $∥·∥_2 = (\sum_{i=1}^N|·|^2)^{\frac{1}{2}}$ stand for the function that outputs the distance between two inputs and L2-norm, respectively.
- $d(·)$ 및 $∥·∥_2 = (\sum_{i=1}^N|·|^2)^{\frac{1}{2}}$는 각각 두 input과 L2-norm 사이의 거리를 출력하는 함수를 나타냄
UAMs can also carry up to $Λ$ passengers, and also know the status of their seats denoted as $Φ_j = \{\phi^1_j,··· ,\phi^λ ··· ,\phi^Λ_j \}$, where $\phi^λ_j$ is defined as follows,
- UAM은 최대 $\Lambda$ 승객을 태울 수 있음, $Φ_j = \{\phi^1_j,··· ,\phi^λ ··· ,\phi^Λ_j \}$로 나타난 좌석의 상태도 알 수 있음
- $\phi^λ_j$는 다음과 같이 정의됨,
→ 즉, $\Lambda$는 좌석 수

→ 승객 $ϱ_ξ$이 UAM $u_j$ 내 $\lambda$번째 좌석에 타고 있다면 $ϱ_ξ$, 아니라면 $-1$
Lastly, each $j$-th UAM has to observe its energy state $e_j$ to avoid the battery’s full discharge for a safe air transportation system denoted as follows,
- $j$번째 UAM은 다음과 같이 표시되는 안전한(safe) 항공 운송 시스템을 위해 배터리의 완전 방전(full discharge)을 피하기 위하여 에너지 상태 $e_j$를 관찰해야 함

where the $P_h$ and $P_p$ stand for power consumption when UAM takes-off or lands on the vertiport defined in Sec. III-B. In addition, $A_h$ and $A_v$ are the action UAM takes, which are specified in Sec. IV-A2.
- 여기서 $P_h$와 $P_p$는 UAM이 III-B에서 정의된 vertiport에 이륙하거나 착륙할 때 전력 소비를 나타냄
- 추진 동력 소비량(propulsion power consumption) $P_p$
- 호버링 전력 지출(hovering power expenditure) $P_h$
- $A_h$와 $A_v$는 IV-A2에 명시된 UAM이 취하는 action
In brief, the partial information that $j$-th UAM can observe in the environment is connoted as follows,
- $j$번째 UAM이 환경에서 observe 가능한 부분적인 정보(partial information)는 다음과 같이 내포

- $p_j$: UAM의 데카르트 좌표, $p_j \in \{x_j , y_j , z_j \}$
- $\bigcup^J{d(u_j,u_{j'})}$: 관찰 범위 내 다른 UAM들와의 거리
- $\bigcup^J{d(u_j,ν_n)}$: 관찰 범위 내 다른 vertiport들과의 거리
- $Φ_j$: 승객 탑승 좌석 정보
- $e_j$: UAM의 에너지 상태(energy state)
2) State: The ground truth state includes the overall air transportation service information consisting of the number of passengers serviced by each UAM represented as $\bigcup^Ξ_{ξ=1}{𝟙_j(ϱ_ξ)}$, where the $𝟙(·)$ is an indicator function differentiating serviced (one) or not (zero).
- ground truth state는 $\bigcup^Ξ_{ξ=1}{𝟙_j(ϱ_ξ)}$로 표시되는 각 UAM이 서비스하는 승객 수로 구성된 전체 항공 운송 서비스 정보를 포함
- 여기서 $𝟙(·)$는 “서비스 ($1$)” 또는 “서비스 안함 ($0$)”을 구별하는 지표 함수(indicator function)
The type of vertiports each UAM landed on is also contained in the ground truth state denoted as $\bigcup^N_{n=1} \{𝟙_j (ν_n)\}$, which represents visited (one) or not (zero).
- 각 UAM이 착륙하는 vertiport의 종류도 “방문함 ($1$)” 또는 “방문하지 않음 ($0$)”을 나타내는 $\bigcup^N_{n=1} \{𝟙_j (ν_n)\}$로 표시되는 ground truth state에 포함됨
Additionally, the distance to the target vertiport of the passenger boarding the $j$-th UAM is one of the components of the state space, which is $d'(u_j, ν^{\text{target}}_n )$. Here, the distance between $u_j$ and $ν^{\text{target}}_n$ dependent on seating state can be defined as follows,
- $j$번째 UAM에 탑승하는 승객의 target vertiport까지의 거리는 state space의 구성 요소 중 하나이며, $d'(u_j, ν^{\text{target}}_n )$임.
- 좌석 상태에 따라 $u_j$와 $ν^{\text{target}}_n$ 사이의 거리는 다음과 같이 정의됨

To recap, the ground truth state can be organized as follows,
요약하자면, ground truth 상태(state) $\mathcal{S}$는 다음과 같이 정리할 수 있음

- $\bigcup^J \bigcup^Ξ \{𝟙_j (ϱ_ξ)\}$: $J$개의 각각의 UAM에 대한, $Ξ$명의 승객의 각각의 탑승 여부
- $\bigcup^J \bigcup^N \{𝟙_j (ν_n)\}$: $J$개의 각각의 UAM에 대한, $N$개의 각각의 vertiport의 방문 여부
- $\bigcup^J \bigcup^\Lambda \{ d'(u_j, ν^{\text{target}}_n) \}$: $J$개의 각각의 UAM에 대한, $Λ$개의 좌석에 탑승한 각각의 승객에 대한 UAM과 해당 승객의 target vertiport까지의 거리

3) Action: In every time step $t$, every UAM can take two types of actions; i) horizontal and ii) vertical moving, where the set of actions is $A≜\{A_h,A_v\}$ as illustrated in Fig. 3. Note that $A_h$ and $A_v$ have an alternate relationship, thus Ah is zero when Av is selected by UAM (vice versa).
- 매 time step $t$에서 모든 UAM은 두 종류의 action을 취할 수 있음
- i) horizontal moving (수평 이동)
- ii) vertical moving (수직 이동)
- action 집합은 위 그림 3과 같이 $A≜\{A_h,A_v\}$임

- $A_h$와 $A_v$는 대체 관계(alternative relationship)를 가지므로 UAM에서 $A_v$를 선택하면 $A_h$는 0이 됨
The first type of action is horizontal moving from one vertiport to another vertiport in ordinal directions expressed in vector form as follows,
- 첫 번째 action 종류는 다음과 같이 벡터 형태로 표시되는 순서대로 한 vertiport에서 다른 vertiport로 수평 이동하는 것으로, 아래와 같이 나타낼 수 있음

→ $x$, $y$로만 이동하며, $z$축이 0
→ $x$축으로만 이동, $y$축으로만 이동, $x$, $y$축 동시에 이동
The other is moving for vertical take-off and landing in any vertiport, which can be indicated in vector form as follows,
- 나머지 종류의 action은 수직 이착륙을 위해 움직이는 것으로, 벡터 형태로 다음과 같이 나타낼 수 있음

→ $z$축만 이동하며, $x$, $y$축은 0
→ $z$축 상승 또는 하강
4) Reward: Every UAM takes action at every time step, and then it gets a reward from reward function $\mathcal{R}(s, a, s' )$ when the state s is transited to the next state s′. There is a common goal of UAMs in MADRL, this paper divides the reward function into two elements; i) individual reward, ii) common reward. Thus, the reward function can be configured as $\mathcal{R}(s,a,s') = \sum^J_{j=1} (\mathcal{R}^j_{\text{Indiv}}(s,a,s')) + \mathcal{R}_{\text{Comm}}(s,a,s')$. First, each UAM receives individual rewards based on its actions. Accordingly, all UAMs have different individual reward values from each other, which are denoted as follows,
- 모든 UAM은 매 time step에서 action을 수행한 후 다음 상태 $s'$로 전환되면 보상 함수 $\mathcal{R}(s, a, s' )$에 따라 보상(reward)을 받음
- MADRL에는 UAM의 공통 목표(common goal)이 있으며, 본 연구에서 보상 함수를 i) 개별 보상(individual reward), ii) 공통 보상(common reward) 두 개로 나누었음
- 따라서, 보상 함수는 $\mathcal{R}(s,a,s') = \sum^J_{j=1} (\mathcal{R}^j_{\text{Indiv}}(s,a,s')) + \mathcal{R}_{\text{Comm}}(s,a,s')$으로 구성됨
- 먼저, 각 UAM은 action을 기반으로 개별 보상을 받음. 따라서, 모든 UAM은 서로 다른 개별 보상 값을 가지며 이 값은 다음과 같이 나타낼 수 있음

where $C_{th}$ and $Γ$ are the minimum distance to occur collision and considered environment size in this paper, respectively.
- $C_{th}$: 충돌 발생(occur collision) 최소 거리(minimum distance)
- $Γ$: 본 논문에서 고려된 환경 크기(environment size)
- $\prod^J𝟙(d(u_j,u_{j'}))\geq C_{th}\times$: UAM $j$와 $j’$사이 거리가 충돌 발생 최소 거리보다 크면 $1$, 작으면 $0$을 곱함
- $\sum^{\Xi}𝟙_j(ϱ_ξ)$: 각 승객에 대한 탑승 여부
- $\sum^N 𝟙_j (ν_n)$: 각 vertiport에 대한 방문 여부
- $-\sum^{\Lambda}\frac{d'(u_j, ν^{\text{target}}_n)}{Γ/2}$: “환경 크기”에 대한 “각 승객에 대한 UAM과 해당 승객의 target vertiport까지의 거리”의 음의 비율 (가까워질수록 보상이 0에 가까워지고, 멀어질수록 보상이 음수로 작아짐)
- $\frac{e_j}{e_{\text{max}}}$: 최대 배터리 에너지 상태에 대한 현재 에너지 상태의 비율 (현재 배터리 용량)
Next, all UAMs have the same common reward value simultaneously which helps them to cooperatively achieve a shared objective without preemption or competition. The common reward is established as follows,
- 다음으로, 모든 UAM은 동시에 동일한 공통 보상 값(common reward value)을 가지므로, 선점이나 경쟁 없이 협력적으로 공유된 목표(shared objective)를 달성할 수 있음. 공통 보상은 다음과 같음

→ 모든 UAM에 대해 각각의 UAM이 서비스하는 승객 수($𝟙_j(ϱ_ξ)$)의 평균값($\sum^J\frac{x}{J}$)
As a result, as seen in the above definition of the reward function, all UAMs try to maximize not only the quality components of air transportation service but also consider safety conditions. By shaping appropriate reward functions, UAMs can learn the intelligence to select the suitable strategy concerning shared objectives in any given state.
- 결과적으로, 위 보상 함수의 정의에서 볼 수 있듯이, 모든 UAM은 항공 운송 서비스의 품질 구성요소(quality components)뿐만 아니라 안전 조건(safety conditions)을 고려하여 최대화하려고 함
- 적절한 보상 함수를 형성함으로써, UAM은 주어진 상태(given state)에서 공유된 목표(shared objectives)와 관련하여 적합한 전략(suitable strategy)을 선택하는 지능을 학습할 수 있음
5) Objective: All UAMs’ main objectives can be mathematically expressed as follows,
모든 UAM의 주요 목표는 수학적으로 아래와 같이 표현할 수 있음

where $θ$, $E$, and $T$ correspond to the parameters of actor-network, environment, and episode length, respectively. In summary, it is obvious that the main objective of UAMs is to find the optimal policy maximizing the expected cumulative reward over a given finite step $T$.
- $\theta$: actor-network parameter
- $E$: environment parameter
- $T$: episode length
- 요약하면, UAM의 주요 목표는 주어진 유한 단계(finite step) $T$에서 예상 누적 보상(expected cumulative reward)을 최대화하는 최적의 정책(optimal policy)을 찾는 것임
IV-B. Information Sharing by CommNet

The CommNet algorithm provides mutual communication between multiple UAMs with a communication step when multiple actors proceed to learn their hidden variables as depicted in Fig. 4. This process of sharing observation information with each other is particularly effective when multiple agents try to achieve a common goal in a Dec-POMDP environment where agents cannot observe the global state.
- CommNet 알고리즘은 그림 4와 같이 여러 Actor가 자신의 hidden variable을 학습하기 위해 진행할 때 여러 UAM 간의 상호 통신(mutual communication)을 통신 단계(communication step)로 제공
- 이러한 observation information을 서로 공유하는 과정은 특히 agent가 전역 상태(global state)를 관찰할 수 없는 Dec-POMDP 환경에서 여러 에이전트가 공통 목표를 달성하려고 할 때 효과적
First of all, every UAM explores the environment consisting of state and observation in Fig. 4(a). Their experiences are encoded into hidden variables of the first layer $h^1_j$ with encoder function in Fig. 4(b) as follows,
- 우선, 모든 UAM은 그림 4(a)에서 state와 observation으로 구성된 환경을 탐색
- 이들의 경험(experiences)은 다음과 같이 그림 4(b)의 인코더 기능으로 첫 번째 layer $h^1_j$의 hidden variable로 인코딩됨

When hidden variables are fed into the deeper hidden layers, the communication variables are entered simultaneously. The communication variable of $j$-th UAM in $i$-th hidden layer is acquired by averaging hidden variables of other UAMs in Fig. 4(c) as follows,
- hidden variable이 더 깊은(deeper) hidden layer에 입력(fed into)되면 통신 변수(communication variables)가 동시에 입력됨
- $i$번째 은닉층의 $j$번째 UAM의 통신 변수는 다음과 같이 그림 4(c)의 다른 UAM의 hidden variable를 평균화하여 획득함

At the input of every $i$-th layer except for the first layer, $h^i_j$ and $c^i_j$ are feed-forwarded to the next layer with the single-agent module $f^i(·)$, which returns output vector $h^{i+1}_j$ as follows,
- 첫 번째 layer를 제외한 모든 $i$번째 layer의 input에서 $h^i_j$ 와 $c^i_j$는 다음과 같이 출력 벡터(output vector) $h^{i+1}_j$를 반환(return)하는 single agent 모듈 $f^i(·)$과 함께 다음 layer로 feed-forward됨

subject to

where $Activ(·)$ and $Concat(·)$ stand for a non-linear activation function (e.g., ReLU, hyperbolic tangent, or sigmoid) and concatenate function. The information sharing by inter- communication between UAMs comes about when averaging hidden variables of different UAMs.
- $Activ(·)$: 비선형 활성화 함수(non-linear activation function) 예를 들어, ReLU, hyperbolic tangent, Sigmoid 등
- $Concat(·)$: Concatenate 함수 (joint)
- UAM 간의 상호 통신(inter-communication)에 의한 정보 공유(information sharing)는 서로 다른 UAM의 hidden variable를 평균화할 때 발생함 ($c^i_j$를 계산하여 획득할 때)
Finally, the action probabilities of $j$-th UAM are obtained by decoding the output of the last layer in Fig. 4(d) as follows,
- 마지막으로, $j$번째 UAM의 action 확률은 그림 4(d)의 마지막 layer의 output을 다음과 같이 디코딩함으로써 얻어짐

where $p(·)$ is the action distribution.
- $p(·)$: action 분포(distribution)
To sum it up, the above sequential process of feed-forwarding can be implied as follows,
- 요약하면, 위와 같은 순차적 피드 포워딩 과정(sequential process of feed-forwarding)은 다음과 같이 나타낼 수 있음

where $Q(o_j,a)$ is commensurate with the action-value function in Dec-POMDP.
- 여기서 $Q(o_j,a)$는 Dec-POMDP의 action-value 가치 함수
It is noteworthy that the output probabilities of $j$-th UAM are also dependent on the network parameters of other UAMs.
- $j$번째 UAM의 output 확률은 다른 UAM의 네트워크 매개 변수(network parameters)에도 의존(dependent on)한다는 점은 주목할 만함
IV-C. CTDE-based Parameterized Policy Training

As motivated in [45], multiple actors distributedly get experiences by exploring environments, and the centralized critic evaluates every global state’s value in Fig. 4(f). The centralized critic may be a central server such as a control tower observed in Fig. 1. This strategy helps all UAMs symmetrically to learn near-optimal policies. Additionally, below introduces the multi-agent policy gradient (MAPG) based on the temporal difference (TD) actor-critic method [46] with Bellman optimality equation to prevent the occurrence of high variance.
- 여러 actor가 분산적으로 환경을 탐색하여 경험을 얻고, 중앙 집중식 Critic은 그림 4(f)의 모든 global state의 가치를 평가
- 중앙 집중식 critic은 그림 1의 관제탑과 같은 중앙 서버(central server)일 수 있음
- 이러한 전략은 모든 UAM이 대칭적으로 최적에 가까운 정책(policy)를 학습하는 데에 도움이 됨
- 아래에서는 높은 분산(high variance) 발생을 방지하기 위해 벨만 최적 방정식(Bellman Optimality Equation)을 사용한 Temporal Difference(TD) Actor-Critic 방법을 기반으로 한 Multi-Agent Policy Gradient (MAPG)을 소개함
Centralized Critic. To evaluate the value of parameterized policies of decentralized actors, the centralized critic tries to learn its network parameters $\phi$ to approximate the optimal joint state-value function which is configured as follows,
- 분산된 Actor의 매개변수화 된 Policy의 가치(value)를 평가하기 위해 centralized Critic은 다음과 같은 Optimal Joint State-Value 함수를 근사화하기 위해 네트워크 매개변수 $\phi$를 학습하고자 함

With (21), the centralized critic learns its network parameters to minimize the loss function which is leveraged as follows,
- 식 (21)을 사용하여 centralized critic은 다음과 같이 활용되는 Loss 함수를 최소화하기 위해 네트워크 매개변수를 학습함

subject to

where $δ_\phi^t$ is the TD error based on Bellman optimality equation in time step $t$. As seen in (23), the TD target is composed of the summation of current and future reward values. Based on (23), the centralized critic trains its network parameters in the direction of minimizing the loss function by gradient descent as follows,
- $δ_\phi^t$: time step $t$에서 Bellman optimal 방정식을 기반으로 한 TD error
- 식 (23)에서 볼 수 있듯 TD Target은 현재 및 미래 보상 값의 합으로 구성됨
- 식 (23)을 기반으로 centralized critic은 다음과 같이 gradient descent에 의한 loss 함수를 최소화하는 방향으로 네트워크 매개 변수를 학습함

where $α_\text{critic}$ stands for a learning rate of the centralized critic network that decides the inclination of updating neural network parameters by policy gradient.
- $α_\text{critic}$: Policy Gradient에 의해 network 매개변수를 업데이트하는 경향(inclination)을 결정하는 centralized critic network의 학습률(learning rate)
Multiple Actors. Actors correspond to UAMs providing air transportation service to passengers in environments. They learn policy parameters $θ$ to approximate optimal policy for providing efficient air transportation service. At every time step $t$, they make sequential decision-making based on their parameterized strategy function as follows,
- actor는 환경에서 승객에게 항공 운송 서비스를 제공하는 UAM에 해당됨
- Agent들은 효율적인 항공 운송 서비스를 제공하기 위한 최적의 정책(optimal policy)를 근사화(approximate)하기 위해 Policy 매개변수 $\theta$를 학습함
- time step $t$마다 agent들은 다음과 같이 매개변수화된 strategy 함수를 기반으로 순차적인(sequential) 의사 결정(decision-making)을 함

It can be seen that each UAM selects an action with high probability among all possible actions as presented in Fig. 4(e). Here, $j$-th UAM’s parameterized policy $π_{θ_j}$ is defined as follows,
- UAM은 그림 4(e)에 제시된 것과 같이 선택 가능한 모든 action 중에서 가장 확률이 높은 action을 선택함
- 여기서 $j$번째 UAM의 매개변수화된 정책(policy) $π_{θ_j}$은 아래와 같이 정의됨

subject to

where $softmax(·)$ stands for exponential softmax distribution function to activate normalization of action probabilities.
- $softmax(·)$: action 확률의 정규화를 활성화(activate)하기 위한 지수 softmax 분포 함수
Finally, the objective function that dispersed actors need to maximize is mathematically constituted as follows,
- 마지막으로 분산된(dispersed) actor들이 최대화해야 하는 목적 함수(objective function)는 아래와 같이 나타낼 수 있음

Using (28), UAMs learn their parameters toward maximizing the objective function by gradient ascent as follows,
- 식 (28)을 사용하여 UAM은 다음과 같이 Gradient Ascent에 의한 목적 함수를 최대화하기 위한 매개 변수를 학습함

where $α_\text{actor}$ is a learning rate of the actor network.
- $α_\text{actor}$: Actor Network의 학습률(learning rate)

The details of the CTDE-based policy training and inference are organized in Algorithm 1 in consecutive order.
- CTDE 기반 Policy Training 및 Inference의 세부 사항은 알고리즘 1에 순차적으로 정리되어 있음
V. Performance Evaluation
V-A. Experimental Setting
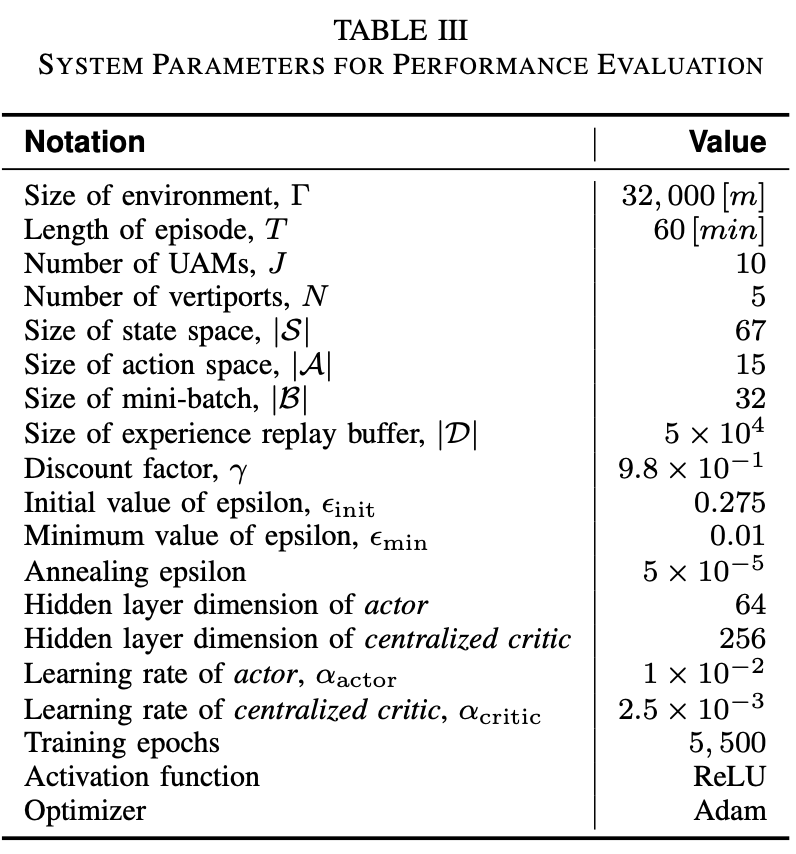
The air transportation area has a size of $(2 × Γ)^2$ $m^2$, illustrated in Fig. 2. In that area, $J$-UAMs autonomously provide air transportation service to passengers by transporting them from one vertiport to the destination vertiport.
- 항공 운송 영역(area)는 그림 2와 같이 $(2 × γ)^2$ $\text{m}^2$의 크기
- 해당 영역에서 $J$-UAM은 하나의 vertiport에서 목적지(target) vertiport로 운송하여, 승객에게 자율적으로 항공 운송 서비스를 제공
As mentioned in Sec. III-B, the realistic UAM model, named JOBY AVIATION’s S4, transports passengers at an altitude of 600m. In addition, this UAM model can carry up to four passengers based on the first-in-first-out (FIFO).
- III-B에서 언급했듯, Joby Aviation의 S4 현실 UAM 모델은 600m 고도에서 승객을 운송함
- 또한, 이 UAM 모델은 FIFO(First-In-First-Out, Queuing) 방식으로 최대 4명의 승객이 탑승 가능
UAMs start an episode at random vertiports, and destinations/departures of passengers also change from episode to episode. In addition, UAMs can recharge their batteries for five minutes at the vertiport while dropping off and picking up passengers as mentioned in Sec. III-B.
- UAM은 랜덤 vertiport에서 에피소드를 시작하고, 승객의 목적지와 출발지도 에피소드마다 변경됨
- UAM은 III-B에서 언급되었듯 vertiport에서 5분간 배터리를 충전할 수 있음
Lastly, note that this paper considers a total of five vertiports, as depicted in Fig. 2. With merely five vertiport locations, the network effectively represents a city-wide, large-scale, and intricate system capable of realistically accommodating a significant number of passengers. In [38], Uber has established five vertiports in the Dallas Metropolitan area, which is the closest region to the implementation of UAM-based air transportation service. Since Uber has already determined the number and location of vertiports based on actual urban traffic demand, a configuration with only five vertiports still results in a relatively complex and practical map. The overall system parameter notations and corresponding values are arranged in Table III.
- 마지막으로, 논문에서 그림 2와 같이 총 5개의 vertiport를 고려함
- 단 5개의 vertiport 위치를 가진 네트워크는 상당한 수의 승객을 현실적으로 수용할 수 있는 도시 전체의 대규모이며 복잡한 시스템을 효과적으로 나타낼 수 있음
- 우버는 Dallas 메트로폴리탄 지역에 5개의 vertiport를 구축했으며, 이는 UAM 기반 항공 운송 서비스 구현과 가장 밀접한 지역이라고 할 수 있음
- 우버는 이미 실제 도시 교통 수요를 기반으로 vertiport의 수와 위치를 결정했기 때문에, 5개의 vertiport만 있는 구성은 복잡하고 실용적인 지도라고 할 수 있음
- 전체 시스템 매개변수 주석과 값은 표 III에 정리되어 있음
V-B. Benchmarks
This paper conducts data-intensive experiments focusing on the validation of the proposed algorithms’ performance, which coincided with i) CommNet and ii) CTDE. For this purpose, this paper divides benchmarks into the following two groups.
- 논문에서 i) CommNet ii) CTDE 와 일치하는 제안된 알고리즘의 성능 검증에 초점을 맞추어 Data-Intensive 실험을 수행
1) Benchmarks for CommNet: To scrutinize the performance of CommNet in MADRL, an ablation study is conducted according to the number of UAMs participating inter-agent communications.
- MADRL에서 CommNet의 성능을 면밀히 조사하기 위해 agent 간 통신에 참여하는 UAM의 수에 따라 절제 연구(ablation study)가 수행
CommNet (Proposed). All UAMs in this benchmark learn their policies with rich experiences (i.e., hidden variables) using information sharing via inter-communications.
- 이 벤치마크의 모든 UAM은 통신을 통한 정보 공유를 사용하여 풍부한 경험(즉, hidden variables)으로 정책을 학습
Hybrid. This benchmark has half CommNet-based UAMs and half DNN-based UAMs, where ’DNN’ stands for the conventional neural network architecture. In other words, only half of UAMs communicate environmental information with each other.
- 이 벤치마크에는 절반의 CommNet 기반 UAM과 절반의 DNN 기반 UAM이 있음
- 즉, 절반의 UAM만이 서로 환경 정보를 전달 및 공유
DNN. There are no mutual communications between UAMs. In other words, they behave as in a single-agent DRL environment.
- UAM 간에는 상호 통신이 없음, Single-Agent DRL 환경처럼 동작함
Monte Carlo. Since UAMs in this benchmark have no policies, they take actions randomly without sequential decision-making. Although it is not an ML/DRL algorithm, it can serve as a standard for evaluating the performance of other learning algorithms.
- UAM은 Policy가 없으므로 순차적인 의사결정 없이 random action을 취함
- ML/DRL 알고리즘은 아니지만 다른 학습 알고리즘의 성능을 평가하는 기준
2) Benchmarks for CTDE: Benchmarks in the other group differ in their training methodology. The performance of the proposed CTDE-based training approach is compared with conventional DRL algorithms.
- 학습 방법에 따라 벤치마크가 다름. 제안된 CTDE 기반 학습 방법의 성능을 기존의 DRL 알고리즘과 비교
CTDE (Proposed). A central server utilizes centralized critic when evaluating the ground truth state made by decentralized actors.
- Centralized Server는 분산된(decentralized) Actor가 만든 ground truth state를 평가할 때 centralized critic을 활용
IAC. Instead of a central server, every UAM has its independent actor-critic (IAC) networks. UAMs in this benchmark learn their policies based on the existing TD actor-critic algorithm [46].
- 모든 UAM은 centralized server 대신 독립적인 IAC(Independent Actor-Critic) 네트워크를 가짐
- 이 벤치마크의 UAM은 기존 TD Actor-Critic 알고리즘을 기반으로 정책을 학습
DQN. Deep Q-network (DQN) algorithm [47] only approximates Q-function without separate neural network approximating optimal state-value function (i.e., critic).
- DQN 알고리즘은 최적(optimal)의 State-Value 함수(즉, Critic)를 근사하는 별도의 network 없이 Q-함수(action-value 함수)만을 근사
Monte Carlo. This benchmark is for the Monte Carlo simulation as described above.
- 이 벤치마크는 위에서 설명한 Monte Carlo 시뮬레이션에 해당
V-C. Training Performance
1) Reward Convergence: Figs. 5–6 plot UAMs’ obtained reward value while training their policies, and Table IV–V summarize the final reward convergence value in both POMDP and FOMDP environments. Note that FOMDP is unrealistic due to UAM model’s physical limitations.
- 그림 5~6은 UAM이 policy을 학습하는 동안 얻은 보상 값을 나타냄
- 표 Ⅳ~V는 POMDP와 FOMDP 환경 모두에서 최종 보상 수렴 값을 요약한 것
- FOMDP는 UAM 모델의 물리적 한계로 인해 비현실적임


Firstly, among benchmarks of the first group, UAMs in CommNet get the fastest reward-increasing rate in Fig. 5, and the most enormous reward value of 0.647 in POMDP and 0.602 in FOMDP as summarized in Table IV. Notably, only the proposed algorithm allows UAMs to get a higher reward in POMDP than FOMDP, regardless of information loss.
On the other side, rewards of UAMs in Hybrid and DNN converge to 0.438 and 0.148, respectively. It means that these schemes are obviously susceptible to information loss in POMDP by getting 3.94% and 56.1% lower reward values than in FOMDP. In the case of DNNs utilizing only DNN-based UAMs, policy training failed with smaller rewards than Monte Carlo. Indeed, the presence of a CommNet-based UAM helps serve robust air transportation service with limited environmental information in MADRL.
- 첫째, 첫 번째 그룹의 벤치마크 중 CommNet의 UAM은 그림 5에서 가장 빠른 보상 증가율을 얻으며, 표 IV에 요약된 바와 같이 POMDP에서 0.647, FOMDP에서 0.602의 가장 높은 보상 값을 얻음
- 특히 제안된 알고리즘만 사용하면 정보 손실과 관계없이 UAM이 FOMDP보다 POMDP에서 더 높은 보상을 받을 수 있음
- 반면 Hybrid와 DNN에서 UAM의 보상은 각각 0.438과 0.148로 수렴
- 이는 이러한 계획이 FOMDP보다 3.94%p와 56.1%p 낮은 보상 값을 얻음으로써 POMDP에서 정보 손실에 분명히 취약하다는 것을 의미
- DNN 기반 UAM만 사용하는 DNN의 경우 MC보다 작은 보상으로 정책 교육에 실패
- 실제로 CommNet 기반 UAM의 존재는 MADRL에서 제한된 환경 정보로 강력한 항공 운송 서비스를 제공하는 데 도움이 됨


Besides, in Fig. 6 and Table V, CTDE outperforms the other DRL benchmarks of the second group in POMDP/FOMDP. UAMs trained by IAC and DQN receive reward values of 0.440 and 0.131 in POMDP. Especially, DQN fails to learn UAMs in both MDP environments by attaining lower reward values of 0.131 and 0.111 than Monte Carlo. According to [48], a limitation of utilizing DQN-based DRL in multi-agent settings is the reduced effectiveness of experience replay.
- 또한 그림 6과 표 V에서 CTDE는 POMDP/FOMDP에서 두 번째 그룹의 다른 DRL 벤치마크보다 성능이 뛰어남
- IAC와 DQN에 의해 훈련된 UAM은 POMDP에서 0.440과 0.131의 보상 값을 받음
- 특히 DQN은 몬테카를로보다 0.131과 0.111의 더 낮은 보상 값을 달성하여 두 MDP 환경 모두에서 UAM을 학습하지 못하는 것으로 판단
- 다중 에이전트 설정에서 DQN 기반 DRL을 활용하는 데 한계는 experience replay의 효율성 감소임
Unlike single-agent scenarios, the same action executed in an identical state may yield varying outcomes, contingent on other agents’ actions. Consequently, agents that have trained neural network parameters through DQN in MARL may struggle to optimize their parameters efficiently. This occurrence leads to agents collectively exhibiting alike inappropriate behavior when encountering similar environmental information.
- 단일 에이전트 시나리오와 달리 동일한 state에서 실행된 동일한 action은 다른 에이전트의 action에 따라 다양한 결과를 산출할 수 있음
- 결과적으로 MARL에서 DQN을 통해 신경망 매개변수를 훈련한 에이전트는 매개변수를 효율적으로 최적화하는 데 어려움. 이러한 현상은 agent가 유사한 환경 정보를 접할 때 동일한 부적절한 action을 집합적으로 나타냄
As a result, adopting random actions, as observed in Monte Carlo, could yield higher rewards than DQN due to the wider action decisions of agents.
- 결과적으로 몬테카를로에서 관찰된 바와 같이 random action을 선택하면 agent의 더 넓은 action 결정으로 인해 DQN보다 더 높은 보상을 산출할 수 있음
Next, among DRL algorithms that successfully trained policies, only CTDE results in higher reward values in POMDP than in FOMDP. In a nutshell, the training performance of the proposed algorithm with CommNet and CTDE is corroborated by showing the powerful reward convergence ability despite information loss.
- 다음으로 정책을 성공적으로 훈련한 DRL 알고리즘 중 CTDE만이 FOMDP보다 POMDP에서 더 높은 보상 값을 도출
- 즉, CommNet과 CTDE를 사용하여 제안된 알고리즘의 훈련 성능은 정보 손실에도 불구하고 강력한 보상 수렴 능력을 보여줌으로써 확증됨


2) Trained Trajectories: This section intuitively investigates the CommNet’s training performance with Fig. 9, which exhibits the trajectories of UAMs trained by CommNet and DNN benchmarks in the POMDP environment. At the last training epoch, it can be seen that CommNet-based UAMs do not deviate much from the considered system map. In contrast, DNN-based UAMs have unnecessary trajectories in terms of air transportation service provision (Agents 4 and 10) or are isolated in a limited area (Agent 3). Some agents are even isolated in areas where vertiports do not exist (Agents 2, 5–6, and 7–9). In addition, it can be seen that UAMs have non-linear trajectories for transporting passengers to target vertiports.
- 이 섹션에서는 POMDP 환경에서 CommNet과 DNN 벤치마크에 의해 훈련된 UAM의 궤적(trajectory)을 보여주는 그림 9를 통해 CommNet의 훈련 성능을 직관적으로 조사함
- 마지막 훈련 시기에는 CommNet 기반 UAM이 고려된 시스템 맵에서 크게 벗어나지 않음을 알 수 있음
- 반면, DNN 기반 UAM은 항공 운송 서비스 제공 측면에서 불필요한 궤적을 갖거나(에이전트 4 및 10) 제한된 영역에 격리됨(에이전트 3).
- 일부 에이전트는 vertiport가 존재하지 않는 지역(에이전트 2, 에이전트 5-6 및 7-9)에도 격리되는 모습을 보였음
UAM’s linear trajectories are likely to provide more ideal air transport services than non-linear trajectories, but not because of ‘safety’ [49]. In aviation systems, there are horizontal and vertical separations to prevent collisions between aircraft [50]. All aircraft must maintain a safe distance to the separation criteria. Especially in unmanned aerial system (UAS) operating without a pilot, the plane must detect and resolve potential collisions on its own. In the case of UAM, since many UAMs fly simultaneously at low altitudes in urban areas, separation must be managed more strictly than normal aircraft. In particular, near congested vertiport where many UAMs take off and landing, since they must fly while avoiding other UAMs, non-linear trajectories are more ideal for transporting large numbers of passengers with safety considerations.
- 또한 UAM은 target vertiport으로 승객을 운송하기 위한 비선형 궤적(non-linear trajectories)을 가지고 있음
- UAM의 선형 궤적은 비선형 궤적보다 더 이상적인 항공 운송 서비스를 제공할 가능성이 높지만 '안전' 때문은 아님
- 항공 시스템에서는 항공기 간의 충돌을 방지하기 위한 수평 및 수직 분리가 있으며 모든 항공기는 분리 기준(separation criteria)에 대한 안전 거리를 유지해야 함
- 특히 조종사 없이 운영되는 무인 항공 시스템(Unmanned Aerial System, UAS)에서는 비행기가 스스로 잠재적인 충돌을 감지하고 이를 해결할 수 있어야 함
- UAM의 경우 많은 UAM이 도시 지역의 낮은 고도에서 동시에 비행하기 때문에 일반 항공기보다 분리를 더 엄격하게 관리해야 함
- 특히 많은 UAM이 이착륙하는 혼잡한 vertiport 근처에서는 다른 UAM을 피하면서 비행해야 하기 때문에 비선형 궤적은 안전을 고려하여 많은 승객을 운송하는 데 더 이상적으로 보임
In Fig. 8, transportation services are relatively concentrated in A, C, D, and E except for B (FORT WORTH). This is the result of considering actual passenger demand. In Fig. 2, the traffic circle connecting Dallas, Texas and Frisco is very busy. In 2018, 27.2 million people visited Dallas, and 40% of Frisco Collin’s residents commute there [38]. So traffic can achieve economies of scale, and there are DFW Airport (A) and Dallas Love Field Airport(D), which are the hubs of air traffic in the heart of the United States, in the metropolitan area. Demand is concentrated at airports with high traffic volumes or at FRISCO between DOWNTOWN DALLAS, where commuting volume is high. In the vertiport map in Fig. 2, the vertiport layout is designed based on these actual passenger demands, so the experimental results shown in Fig .8 are also very reasonable.
- 그림 8에서 교통 서비스는 B(Fort Wars)를 제외하고는 상대적으로 A, C, D, E에 집중되어 있는데, 이는 실제 승객 수요를 고려한 결과임
- 그림 2에서 Dallas, Texas, Frisco를 연결하는 traffic circle는 매우 분주함
- 2018년에는 2,720만 명이 Dallas를 방문했으며, Frisco Collin’s 거주자의 40%가 그곳으로 통근함
- 따라서 교통은 규모의 경제(economies of scale)를 달성할 수 있으며, 미국의 심장부 항공 교통의 허브인 DFW 공항(A)과 Dallas Love Field 공항(D)이 수도권에 있음
- 교통량이 많은 공항이나 통근량이 많은 Dallas 도심 사이의 Frisco에 수요가 집중되어 있음
- 그림 2의 vertiport 맵에서는 이러한 실제 승객 수요를 바탕으로 vertiport 배치를 설계하고 있어 그림 8과 같은 실험 결과도 매우 합리적이라고 할 수 있음

More exact values are organized in Fig. 10, where the total type of vertiport CommNet-based UAMs landed on is twice as DNN-based UAMs. In addition, every CommNet-based UAM landed on various vertiports on average 2.3 times more than a DNN-based UAM. It is also confirmed that all CommNet-based UAMs successfully transported passengers by visiting at least more than two different vertiports, with the maximum types of vertiports being visited even reaching four (Agents 5 and 6). However, in DNN, only three UAMs (Agents 1, 5, and 8) landed on more than two different vertiports, and the maximum type of visited vertiport is less than the CommNet.
- 보다 정확한 값은 그림 10에 정리되어 있으며, 여기서 CommNet 기반 UAM의 총 유형은 DNN 기반 UAM의 2배
- 또한 모든 CommNet 기반 UAM은 DNN 기반 UAM보다 평균 2.3배 더 다양한 버티포트에 착륙하였음
- 또한 모든 CommNet 기반 UAM이 최소 2개 이상의 서로 다른 버티포트를 방문하여 승객을 성공적으로 운송했으며, 최대 유형의 버티포트가 4개(에이전트 5 및 6)에 도달하는 것으로 확인되었음
- 그러나 DNN에서는 3개의 UAM(에이전트 1, 5 및 8)만이 2개 이상의 서로 다른 버티포트에 착륙했으며 최대 방문 버티포트 유형은 CommNet보다 적은 것을 확인할 수 있음
3) Equity in Policy Training: A MARL algorithm is meaningless if at least one agent fails to learn the policy, even if it goes through the training process and achieves a high total reward value. Therefore, to ensure that all UAMs have equally well-trained their policies, Fig. 7 provides the convergence behavior of every UAM trained by the proposed CommNet/CTDE-based MADRL algorithm.
- MARL 알고리즘은 학습 과정을 거쳐 높은 총 보상 값을 달성하더라도 적어도 하나의 에이전트가 정책을 학습하지 못하면 의미가 없음
- 따라서 모든 UAM이 동등하게 정책을 잘 훈련했는지 확인하기 위해 그림 7은 제안된 CommNet/CTDE 기반 MADRL 알고리즘에 의해 학습된 모든 UAM의 수렴 양상(convergence behavior)을 보여줌
All UAMs show similar tendencies in learning policies, starting with an average reward value of 0.0203 ranging from 0.0119 to 0.0274. At the end of the training, all UAMs get reward values of 0.0348–0.0765. Here, the average value is 0.0564, which is 53.01 % higher than the average reward value of Monte Carlo (≈ 0.0265) summarized in Tables IV and V. As a result, it is confirmed that all UAMs trained by the proposed algorithm have equitable training performance.
- 모든 UAM은 0.0119에서 0.0274 범위의 평균 보상 값 0.0203에서 시작하여 학습 정책에서 유사한 경향을 보임
- 학습이 끝나면 모든 UAM은 0.0348–0.0765의 보상 값을 얻음, 여기서 평균값은 0.0564로 표 IV 및 V에 요약된 MC(≈ 0.0265)의 평균 보상 값보다 53.01%p 높음
- 결과적으로 제안된 알고리즘에 의해 훈련된 모든 UAM은 공평한 학습 성능(equitable training performance)을 보임을 확인할 수 있었음
V-D. Feasibility of the Proposed Air Transportation System
This section evaluates the feasibility of the proposed air transportation network in versatile aspects with 100 inference times in the POMDP environment. For feasibility studies, this paper adopts the quality of air transportation service, UAMs’ unbiased performance, and energy management as evaluation indicators.
- 본 절에서는 POMDP 환경에서 추론 횟수 100회로 제안된 항공 교통망의 타당성(feasibility)을 다목적의 측면(versatile aspects)에서 평가함
- 타당성 조사를 위해 본 논문에서는 항공 교통 서비스 품질, UAM의 편차 없는 성능, 에너지 관리 등을 평가 지표로 채택하였음
1) Service Quality: The air transportation service quality considered in this paper encompasses the number of serviced passengers and the number/types of landing vertiports. Successfully transporting many passengers to their destination vertiports is the most crucial element of air transportation services. In addition, the above quality factors are correlated since the more diverse vertiports UAM visits, the more passengers it can provide air transportation services to.
- 본 논문에서 고려한 항공 운송 서비스 품질은 서비스를 제공하는 승객의 수와 착륙한 vertiport의 개수/종류를 포괄함
- 많은 승객을 target vertiport로 성공적으로 운송하는 것은 항공 운송 서비스의 가장 중요한 요소
- 또한, UAM 방문이 다양할수록 승객에게 항공 운송 서비스를 제공할 수 있기 때문에 위와 같은 품질 요소(quality factors)는 상관관계가 있음

Fig. 11 presents the service quality of the first benchmark group. It can be seen that UAMs in CommNet outperform regarding air transportation service quality, except for less than two UAMs. Furthermore, it is noteworthy that among all UAMs trained by other benchmark algorithms that outperform UAMs in the proposed MADRL algorithm, CommNet-based UAMs in Hybrid are unique, corresponding to agent 2 in Fig. 11(a) and agents 1, 2 in Figs. 11(b)–(c). The other DNN- based UAMs in Hybrid and DNN show inferior validation performance to CommNet-based UAMs in CommNet and Hybrid. This result definitely verifies that inter-agent communications by CommNet can help UAMs learn optimal policies to serve autonomous air transportation services.
- 그림 11은 첫 번째 벤치마크 그룹의 서비스 품질을 보여줌
- CommNet의 UAM은 2개 미만의 UAM을 제외하고는 항공 운송 서비스 품질과 관련하여 성능이 우수함
- 또한 제안된 MADRL 알고리즘에서 UAM을 능가하는 다른 벤치마크 알고리즘에 의해 훈련된 모든 UAM 중 Hybrid의 CommNet 기반 UAM은 그림 11(a)의 에이전트 2와 그림 11(b)-(c)의 에이전트 1, 2에 해당하는 고유한 UAM임
- Hybrid 및 DNN의 다른 DNN 기반 UAM은 CommNet 및 하이브리드의 CommNet 기반 UAM보다 검증 성능이 떨어짐
- 이 결과는 CommNet에 의한 agent 간 통신이 UAM이 자율 항공 운송 서비스를 제공하기 위한 최적의 정책을 학습하는 데 도움이 될 수 있음을 확인할 수 있었음

Regarding the second benchmark group’s service quality, UAMs in CTDE outperform others in all service quality factors except for agents 2 and 6 according to Fig. 12. Even though these two UAMs provided the second-highest quality of service, they served similar quality of air transportation service to other IAC agents. Even though these two UAMs provided the second highest quality of service, they served comparable air transportation services to other UAMs in IAC. Moreover, they outperformed UAMs in DQN and Monte Carlo. In the case of DQN, as shown in Fig. 12(a), UAMs cannot serve air transportation service to any passenger similar to the training process in Fig. 6.
- 두 번째 벤치마크 그룹의 서비스 품질과 관련하여, 그림 12에 따르면, CTDE의 UAM은 에이전트 2와 6을 제외한 모든 서비스 품질 요소에서 다른 것보다 성능이 뛰어남
- 이 두 UAM은 두 번째로 높은 서비스 품질을 제공했음에도 불구하고, 다른 IAC 에이전트와 유사한 품질의 항공 운송 서비스를 제공하였음
- 이 두 UAM은 두 번째로 높은 서비스 품질을 제공했음에도 불구하고, IAC의 다른 UAM과 견줄만한 항공 운송 서비스를 제공했음
- 더욱이, 그들은 DQN과 MC에서의 UAM보다 성능이 뛰어났음
- DQN의 경우, 그림 12(a)와 같이 UAM은 그림 6의 학습 과정과 유사하게 어떤 승객에게도 항공 운송 서비스를 제공할 수 없었음

Finally, Table VI summarizes the average validation performance of all UAMs trained with each benchmark represented in Figs. 11–12. It can be seen that the proposed training scheme with CommNet and CTDE algorithms shows the best air transportation performance in terms of the number of serviced passengers and the number/types of vertiports on which UAMs land. The benchmark with the second-highest air transportation performance is IAC consisting entirely of CommNet-based UAMs. Next, Hybrid follows with the third highest air transportation performance. The other learning benchmarks, which correspond to DNN and DQN, failed to train parameterized policies of UAMs by serving inferior performance than Monte Carlo which is not a learning algorithm. In summary, it is confirmed that environmental information sharing by CommNet and training strategy based on CTDE are suitable for building efficient autonomous air transportation networks.
- 마지막으로 표 VI는 그림 11-12에 대표되는 각 벤치마크로 학습된 모든 UAM의 평균 검증 성능을 요약한 것
- CommNet과 CTDE 알고리즘을 적용한 제안된 학습 방식은 서비스 승객 수와 UAM이 착륙하는 버티포트 수/종류 측면에서 가장 우수한 항공 운송 성능을 보였음
- 두 번째로 항공 운송 성능이 높은 벤치마크는 전적으로 CommNet 기반 UAM으로 구성된 IAC임
- 다음으로 Hybrid가 세 번째로 높은 항공 운송 성능을 보여줌
- DNN과 DQN에 해당하는 다른 학습 벤치마크는 학습 알고리즘이 아닌 Monte Carlo보다 성능이 떨어져 매개변수화된 UAM의 정책을 훈련하지 못하였다고 판단함
- 요약하면 CommNet에 의한 환경 정보 공유와 CTDE에 기반한 학습 전략이 효율적인 자율 항공 운송 네트워크를 구축하는 데 적합한 것으로 확인됨

2) Service Fairness: This section inspects in detail the quality of air transportation services of all UAMs. Fig. 13 provides the records of serving air transportation services in POMDP of benchmarks that outperform Monte Carlo in Table VI, which corresponds to the proposed, Hybrid, and IAC algorithms, with 100 inference times. As shown in Fig. 13(a), agent 1 in the proposed algorithm has served the largest number of services, providing air transportation service to 8 passengers. Additionally, agent 2 has visited all vertiports in the environment as shown in Fig. 13(g). In addition to these best records, UAMs in the proposed algorithm have shown the highest and fairest air transportation service than the other benchmarks without an inferior UAM. However, there are UAMs with inferior performance to other benchmarks, such as agents 7-10 in Hybrid and agents 3, 5, and 7–9 in IAC. Note that DNN-based UAMs (Agents 6–10) perform relatively inferior to CommNet-based UAMs (Agents 1–5) in Hybrid.
- 이 절에서는 모든 UAM의 항공 운송 서비스 품질을 자세히 검사함
- 그림 13은 제안된 Hybrid 및 IAC 알고리즘에 해당하는 표 VI에서 MC를 능가하는 벤치마크의 POMDP에서 항공 운송 서비스를 제공한 기록을 볼 수 있으며, 이는 100번의 추론 횟수로 제안된 알고리즘과 일치함
- 그림 13(a)와 같이 제안된 알고리즘의 Agent 1은 8명의 승객에게 항공 운송 서비스를 제공하며 가장 많은 서비스를 제공하였음, 또한 Agent 2는 그림 13(g)와 같이 환경의 모든 vertiport를 방문하였음
- 이러한 최고 기록 외에도 제안된 알고리즘의 UAM은 열등한 UAM 없이 다른 벤치마크보다 가장 높고 공정한 항공 운송 서비스를 보여줌
- 그러나 하이브리드의 Agent 7-10과 IAC의 Agent 3, 5, 7-9와 같이 다른 벤치마크보다 성능이 떨어지는 UAM이 존재함, 하이브리드의 경우 DNN 기반 UAM(Agents 6-10)이 CommNet 기반 UAM(Agents 1-5)보다 성능이 상대적으로 열악한 것을 확인할 수 있음

Table VII shows the variance of all service quality factors represented in Fig. 13. Notably, it can be confirmed that UAMs trained with the proposed algorithm have the smallest variance than Hybrid and IAC while achieving the highest service quality as known in Fig. 13. These results demonstrate that all UAMs in the proposed MADRL strategy cooperate unbiasedly to construct a high-quality autonomous air transportation network.
- 표 VII는 그림 13에 표시된 모든 서비스 품질 인자(service quality factors)의 분산을 보여줌
- 특히, 제안된 알고리즘으로 훈련된 UAM은 그림 13에 알려진 바와 같이 가장 높은 서비스 품질을 달성하면서 Hybrid 및 IAC보다 분산이 가장 작은 것을 확인할 수 있음
- 이러한 결과는 제안된 MADRL 전략의 모든 UAM이 고품질의 자율 항공 교통망을 구축하기 위해 편향되지 않고 협력함을 보여줌
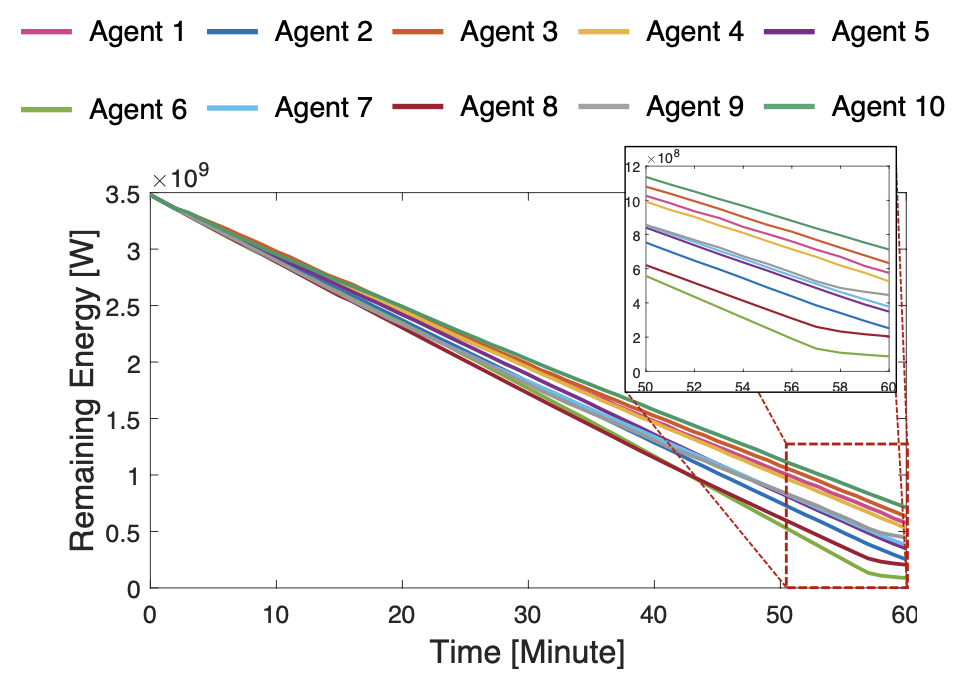
3) Energy Management: The reward function is designed in the direction of preventing the battery from being completely discharged with energy-related observation information when UAM learns its policy in Sec. IV-A4. Fig. 14 shows the energy state of all UAMs in the progress of the episode. It can be observed that UAMs trained by the proposed MADRL algorithm consume their energy within the maximum energy capacity limit for a given episode length $T$. In particular, agents 6 and 8 prevent complete discharging by reducing their energy consumption near the end of the episode.
- 보상 함수는 IV-A4절에서 UAM이 정책을 학습할 때 에너지 관련 observation 정보로 배터리가 완전히 방전되는 것을 방지하는 방향으로 설계되었음
- 그림 14는 에피소드 진행 과정에서 모든 UAM의 에너지 상태를 보여주는데, 제안된 MADRL 알고리즘에 의해 훈련된 UAM은 주어진 에피소드 길이 $T$ 동안 최대 에너지 용량 제한 내에서 에너지를 소비하는 것을 관찰할 수 있음
- 특히 에이전트 6과 8은 에피소드가 끝날 때 즈음 에너지 소비를 줄임으로써 완전 방전을 방지하였음
Hence, it is confirmed that UAMs successfully optimized their policies in both service quality and energy management.
- 따라서 UAM은 서비스 품질과 에너지 관리 모두에서 성공적으로 정책을 최적화한 것으로 확인됨
V-E. Discussions
This section analyzes the above training and inference results in detail by describing the effects of CommNet and CTDE, the proposed training methods in this paper.
- V-E에서는 본 논문에서 제안하는 훈련 방법인 CommNet과 CTDE의 효과를 설명함으로써 위의 학습 및 추론 결과를 자세히 분석
1) Effect of CommNet: As mentioned, the justification for using CommNet lies in achieving a common objective through mutual communication between UAMs. To evaluate the effect of CommNet, this paper conducted an ablation study according to the number of CommNet-based UAMs. The supremacy of this inter-communication scheme is confirmed in Fig. 5 and Table IV by accomplishing the highest reward between all benchmarks in the training phase. In particular, it is meaningful for agent-to-agent communication through CommNet because UAMs in the proposed algorithm obtained a higher reward than FOMDP despite information loss in POMDP.
- 언급한 바와 같이 CommNet을 사용하는 이유는 UAM 간의 상호 통신(mutual communication)을 통해 공통의 목적(common objective)을 달성하는 데 있음
- CommNet의 효과를 평가하기 위해 본 논문은 CommNet 기반 UAM의 수에 따른 절제 연구(ablation study)를 수행했음
- 이러한 상호 통신(inter-communication) 방식의 우월성은 학습 단계에서 모든 벤치마크 간에 가장 높은 보상을 달성함으로써 그림 5와 표 IV에서 확인할 수 있음
- 특히 제안된 알고리즘의 UAM이 POMDP의 정보 손실에도 불구하고 FOMDP보다 더 높은 보상을 얻었기 때문에 CommNet을 통한 에이전트 간 통신에 의미가 있다고 할 수 있음
Furthermore, CommNet-based information sharing helps UAMs learn out-of-range environmental information, allowing them to transport passengers efficiently to diversified vertiports as illustrated in Fig. 9. Next, the performance of the air transportation service quality provided after the learning phase is presented in Fig. 11. In the inference phase, the proposed strategy consisting of only CommNet-based UAMs served the best quality of service, as in the learning phase. Furthermore, parameter-sharing while training policies can make all policies optimal without any inferior UAMs as observed in Figs. 7 and 13, and Table VII.
- 또한 CommNet 기반 정보 공유는 UAM이 범위 밖의 환경 정보를 학습하는 데 도움이 되어 그림 9와 같이 승객을 여러 종류의 vertiport로 효율적으로 운송할 수 있음
- 다음으로 학습 단계 후 제공되는 항공 운송 서비스 품질의 성능이 그림 11에 제시됨
- 추론 단계에서는 CommNet 기반 UAM으로만 구성된 제안된 전략이 학습 단계에서와 마찬가지로 최상의 서비스 품질을 제공했음
- 또한 학습 정책 중 매개변수 공유는 그림 7과 표 VII에서 관찰된 것과 같이 열등한 UAM 없이 모든 정책을 최적화할 수 있었음
2) Effect of CTDE: In addition to CommNet, this subsection investigates the effect of utilizing a centralized critic for CTDE. Since the critic network evaluating the value of every state also needs to be trained to proceed with the episode, so using one centralized critic can serve as a solid standard for multiple actors to learn the policy with fewer episodes than when utilizing independent actor-critic strategy [46].
- 이 subsection에서는 CommNet 외에도 CTDE에 대한 centralized critic 활용 효과를 조사
- 모든 state의 value(가치)를 평가하는 critic 네트워크도 에피소드를 진행하기 위해 학습이 필요하기 때문에 하나의 centralized critic을 사용하면 독립적인 Actor-Critic(IAC) 전략을 사용할 때보다 적은 에피소드로 여러 actor가 정책을 학습할 수 있는 견고한 기준이 될 수 있음
The advantage of CTDE in both training and inference processes is well represented in Fig. 6 and Table V, where training performance is different depending on the learning method if the same number of CommNet-based UAMs are employed. Indeed, since the centralized critic network can learn $J$-times more according to the progress of training epochs and establish more firm criteria for judging the state value than each independent critic network, the fastest convergence was achieved with the highest reward as depicted in Fig. 6. In addition, UAMs trained with a centralized critic network outperform other benchmarks in the inference phase in Fig. 12.
- 학습 및 추론 과정 모두에서 CTDE의 이점은 그림 6과 표 V에 잘 나타나 있으며, 동일한 수의 CommNet 기반 UAM이 사용되는 경우 학습 방법에 따라 훈련 성과가 다름
- 실제로 centralized critic 네트워크는 학습 epoch의 진행에 따라 $J$배 더 많이 학습하고 각 independent critic 네트워크보다 state value을 판단하는 더 확고한 기준을 확립할 수 있기 때문에 그림 6과 같이 가장 높은 보상으로 가장 빠른 수렴을 달성할 수 있었음
- 또한 centralized critic 네트워크로 훈련된 UAM은 그림 12에서 추론 단계에서 다른 벤치마크보다 성능이 뛰어남
Finally, the existence of a firm criterion for evaluating state values ensures that all multiple actors have uniformly superior policies as shown in Figs. 7 and 13, and Table VII.
- 마지막으로 state value를 평가하는 확고한 기준의 존재는 그림 7과 13, 표 VII와 같이 모든 여러 actor가 균일하게 우수한 정책(uniformly superior policies)을 갖도록 함
VI. Conclusions and Future Work
This work aims to efficiently manage autonomous air transportation systems utilizing CommNet and CTDE-based MADRL algorithm. In particular, this paper conducts a realistic evaluation by adopting an actual vertiport map and considering the POMDP environment. Through extensive numerical results, it is demonstrated that the proposed MADRL algorithm has the most superior performance among conventional DRL algorithms in terms of air transportation service quality by helping multiple UAMs cooperatively learn their policies to coordinate their actions.
- 본 연구는 CommNet 및 CTDE 기반의 MADRL 알고리즘을 활용하여 자율 항공 운송 시스템을 효율적으로 관리하는 것을 목표로 함
- 특히 논문에서는 실제 vertiport 맵을 채택하고 POMDP 환경을 고려하여 현실적인 평가를 수행
- 광범위한 수치 결과(extensive numerical results)를 통해 제안된 MADRL 알고리즘은 여러 UAM이 협력적으로 정책을 학습하여 action을 coordinate할 수 있도록 도와줌으로써, 항공 운송 서비스 품질 측면에서 기존 DRL 알고리즘 중 가장 우수한 성능을 가지고 있음을 입증
In addition, all UAMs trained with the proposed strategy serve unbiased air transportation service without any inferior UAMs. In other words, the proposed MADRL algorithm has the most robust policy training performance for information loss in POMDP, effectively reflecting the physical limitations of UAM model.
- 또한 제안된 전략으로 훈련된 모든 UAM은 열등한(inferior) UAM 없이 편차 없는 항공 운송 서비스를 제공
- 즉 제안된 MADRL 알고리즘은 POMDP에서 정보 손실에 대한 가장 강력한 정책 학습 성능을 가지고 있어 UAM 모델의 물리적 한계를 효과적으로 반영
Since UAM-based air transportation services are not yet commercialized, the scale outlined in this paper is suitable for preliminary air transportation service considerations. Nevertheless, once UAM materializes in the future, it would be advantageous to take into account a larger number of UAMs. Indeed, as demonstrated in [51], the MARL-based approach has the potential for scalability and the capacity to handle a considerable number of agents.
- 아직 UAM 기반 항공 운송 서비스가 상용화되지 않았기 때문에 본 논문에서 설명하는 규모는 예비 항공 운송 서비스(preliminary air transportation service) 고려 사항에 적합함
- 그럼에도 불구하고, 향후 UAM이 구체화(materializes)되면 더 많은 수의 UAM을 고려하는 것이 유리할 것
- 실제로 [51]에서 입증된 바와 같이 MARL 기반 접근 방식은 확장성(scalability)과 상당한 수의 에이전트를 처리할 수 있는 잠재력(potential)을 가지고 있음
Lastly, in order to improve the quality of the autonomous air transportation service, it is also a promising direction to consider incorporating factors that take passenger comfort into account in our reward function.
- 마지막으로, 자율 항공 운송 서비스의 품질을 향상시키기 위해 승객의 편안함(passenger comfort)을 고려한 요소를 보상에 통합하는 것도 유망한 방향임