안녕하세요 오늘은 전공 과목인 Signal Processing (신호처리) 과목에서 과제로 발표를 하게 된 Intern Image 논문에 대해서 정리해보겠습니다.


Compared to the great progress of large-scale vision transformers (ViTs) in recent years, large-scale models based on convolutional neural networks (CNNs) are still in an early state.
최근 몇 년간 대규모 비전 트랜스포머(ViT)가 크게 발전한 것에 비해 합성곱 신경망(CNN)을 기반으로 한 대규모 모델은 아직 초기 단계에 머물러 있습니다.
This work presents a new large-scale CNN-based foundation model, termed InternImage, which can obtain the gain from increasing parameters and training data like ViTs.
이 연구에서는 ViT와 같이 파라미터를 늘리고 데이터를 훈련하여 이득을 얻을 수 있는 새로운 대규모 CNN 기반 기초 모델인 InternImage를 소개합니다.
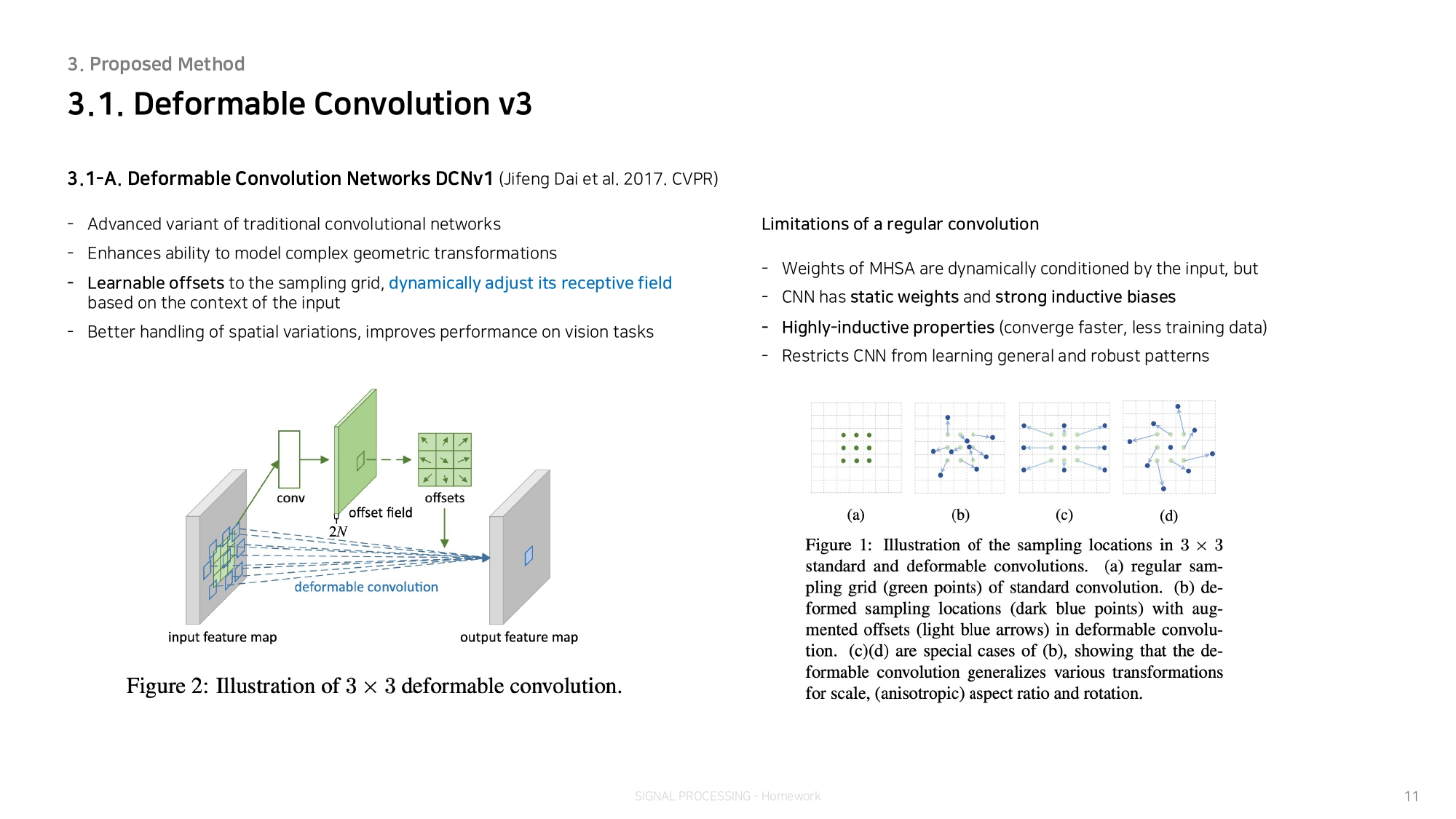
Different from the recent CNNs that focus on large dense kernels, InternImage takes deformable convolution as the core operator, so that our model not only has the large effective receptive field required for downstream tasks such as detection and segmentation, but also has the adaptive spatial aggregation conditioned by input and task information.
대규모 고밀도 커널(Large Dense Kernel)에 초점을 맞춘 최근의 CNN과는 달리, InternImage는 변형 가능한 컨볼루션(deformable convolution)을 핵심 연산자로 사용하기 때문에 detection 및 segmentation과 같은 다운스트림 작업에 필요한 큰 유효 수용 필드(large effective receptive field)를 가질 뿐만 아니라 입력 및 작업 정보에 따라 조절되는 적응형 공간 집계(adaptive spatial aggregation)를 갖습니다.
As a result, the proposed InternImage reduces the strict inductive bias of traditional CNNs and makes it possible to learn stronger and more robust patterns with large-scale parameters from massive data like ViTs.
그 결과, 제안된 InternImage는 기존 CNN의 엄격한 귀납적 편향을 줄이고 ViT와 같은 대규모 데이터에서 대규모 파라미터로 더 강력하고 견고한 패턴을 학습할 수 있습니다.
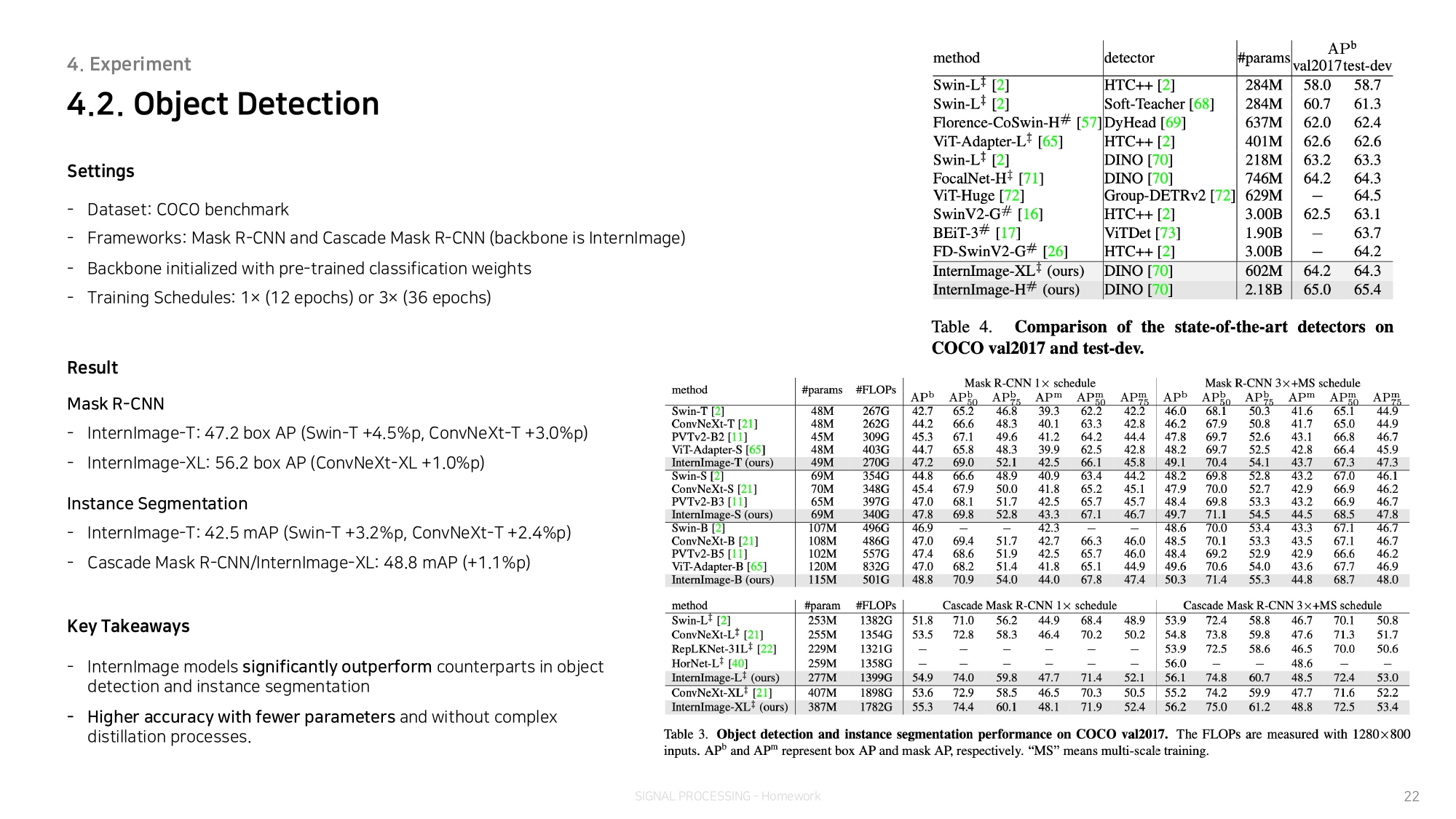
The effectiveness of our model is proven on challenging benchmarks including ImageNet, COCO, and ADE20K.
이 모델의 효과는 ImageNet, COCO, ADE20K 등 까다로운 벤치마크에서 입증되었습니다.
It is worth mentioning that InternImage-H achieved a new record 65.4 mAP on COCO test-dev and 62.9 mIoU on ADE20K, outperforming current leading CNNs and ViTs.
InternImage-H는 COCO 테스트 개발에서 65.4 mAP, ADE20K에서 62.9 mIoU라는 신기록을 달성하며 현재 최고의 CNN과 ViT를 능가하는 성능을 보였습니다.


With the remarkable success of transformers in large- scale language models [3–8], vision transformers (ViTs) [2, 9–15] have also swept the computer vision field and are becoming the primary choice for the research and practice of large-scale vision foundation models.
대규모 언어 모델에서 트랜스포머의 놀라운 성공[3-8]과 함께 비전 트랜스포머(ViT)[2, 9-15]도 컴퓨터 비전 분야를 휩쓸며 대규모 비전 기반 모델의 연구 및 실습을 위한 주요 선택이 되고 있습니다.
Some pioneers [16–20] have made attempts to extend ViTs to very large models with over a billion parameters, beating convolutional neural networks (CNNs) and significantly pushing the performance bound for a wide range of computer vision tasks, including basic classification, detection, and segmentation.
일부 선구자[16-20]들은 ViT를 10억 개 이상의 파라미터를 가진 초대형 모델로 확장하여 컨볼루션 신경망(CNN)을 능가하고 기본 분류, 감지 및 분할을 포함한 광범위한 컴퓨터 비전 작업의 성능 한계를 크게 뛰어넘으려는 시도를 했습니다.
While these results suggest that CNNs are inferior to ViTs in the era of massive parameters and data, we argue that CNN-based foundation models can also achieve comparable or even better performance than ViTs when equipped with similar operator-/architecture-level designs, scaling-up parameters, and massive data.
이러한 결과는 대규모 파라미터와 데이터 시대에 CNN이 ViT보다 열등하다는 것을 시사하지만, 유사한 operator-/architecture-level의 설계, 확장 파라미터(scaling-up parameters), 대규모 데이터를 갖춘 경우 CNN 기반 기반 모델도 ViT와 비슷하거나 더 나은 성능을 달성할 수 있다고 주장합니다.
To bridge the gap between CNNs and ViTs, we first summarize their differences from two aspects:
CNN과 ViT의 차이를 좁히기 위해 먼저 두 가지 측면에서 그 차이점을 요약해 보겠습니다:
(1) From the operator level [9, 21, 22], the multi-head self-attention (MHSA) of ViTs has long-range dependencies and adaptive spatial aggregation (see Fig. 1(a)). Benefiting from the flexible MHSA, ViTs can learn more powerful and robust representations than CNNs from massive data.
(1) 연산자 수준에서 보면[9, 21, 22], ViT의 multi-head self-attention(MHSA)는 장거리 종속성(long-range dependencies)과 적응적 공간 집계(adaptive spatial aggregation)를 가지고 있습니다 (그림 1(a) 참조). 유연한 MHSA의 이점을 활용하여 ViT는 방대한 데이터에서 CNN보다 더 강력하고 강력한 표현을 학습할 수 있습니다.
(2) From the architecture view [9, 22, 23], besides MHSA, ViTs contain a series of advanced components that are not included in standard CNNs, such as Layer Normalization (LN) [24], feed-forward network (FFN) [1], GELU [25], etc.
(2) 아키텍처 관점에서 볼 때[9, 22, 23], MHSA 외에도 ViT에는 Layer Normalization(LN)[24], feed-forward network(FFN)[1], GELU[25] 등과 같이 표준 CNN에 포함되지 않은 일련의 고급 구성 요소(advanced components)가 포함되어 있습니다.
Although recent works [21, 22] have made meaningful attempts to introduce long-range dependencies into CNNs by using dense convolutions with very large kernels (e.g., 31×31) as shown in Fig. 1 (c), there is still a considerable gap with the state-of-the-art large-scale ViTs [16, 18–20, 26] in terms of performance and model scale.
최근 연구[21, 22]에서 그림 1 (c)와 같이 매우 큰 커널(예: 31×31)의 고밀도 컨볼루션(dense convolutions)을 사용하여 CNN에 장거리 의존성(long-range dependencies)을 도입하려는 의미 있는 시도가 있었지만, 성능 및 모델 규모 측면에서 여전히 최첨단 대규모 ViT[16, 18-20, 26]와는 상당한 격차가 존재합니다.